Food Processors Comparison Charts — Bestsellers
This post may contain affiliate links for products I mention. If you click a link and buy something I may receive some compensation. This does not change the price you would pay.
Shopping for a food processor can be overwhelming because there are so many choices – but you’ve come to the right place!
These comparison charts are designed to help you narrow down the selection to find the best appliance for your needs. Models are grouped into the charts according to size, Large, Medium, and Small. You can scroll down the page to see each chart, or just click on the Table of Contents to quickly select the the chart you’d like to see.
(Not sure where to start? For an overview please also see my Food Processor Reviews and Buying Guide.
Table of Contents
- Large Capacity Food Processors – 10 to 16 Cups
- Medium Capacity Food Processors – 7 to 9 Cups
- Small Capacity Food Processors – Up to 3.
5 Cups
- Notes About These Food Processor Comparison Charts
Large Capacity Food Processors – 10 to 16 Cups
These are the largest food processors on the market for home use. (The next step up is to commercial food processors.) The largest size is best suited for those who cook a lot, cook for large families, or cook in volume for any reason. Maximum capacity is also important to gardeners at harvest time!
One of these models is also your best choice if you plan to knead dough because most often you’ll need the large bowl for best results.
The only downside is size, so before you buy, be sure to consider your available counter space, as well as cabinet space for storage.
Medium Capacity Food Processors – 7 to 9 Cups
A medium capacity food processor can be a good compromise when kitchen space is limited. Just keep in mind that in addition to having a smaller processing bowl, most of these models also have less power than the larger models (you can look at the Watts listed in the tables to compare).
Small Capacity Food Processors – Up to 3.5 Cups
None of these small food processors can hold a candle to some of the larger workhorses in the tables above. However, smaller models are very handy for quick little jobs when you don’t want to pull out your larger unit. They are also inexpensive enough that many people enjoy having both a larger machine as well as one of these small units. In fact, when you want to process just a small bit of something, such as a few pods of garlic, a small food processor will actually do a much better job.
Of course, these small units are also a great choice for singles, for those with tiny kitchens, or for anyone who wouldn’t really use all the bells and whistles you get on the bigger models. Some are priced so low they would make great stocking stuffers for the cooks on your list.
Notes About These Food Processor Comparison Charts
All food processor models shown in the tables rank among the top 20 online best sellers. In each table, the models are grouped by size, starting with the largest capacity models of that group on the left and going down.
In each table, the models are grouped by size, starting with the largest capacity models of that group on the left and going down.
In the rows labeled “Color” (in any of the tables), terms such as “stainless”, “brushed stainless”, and “brushed chrome” refer to the color only and do not necessarily indicate the type of construction material.
The images shown in the tables are served by Amazon, and they are not to scale. To see the actual dimensions of a food processor please refer to our reviews or click to go to Amazon and see the information there.
The comparison charts and information on this page are provided to help save you time in sorting through all the choices so you can select the best food processor for you.
If you found this information helpful please share on Pinterest to help others!
Credit Card Processor Comparison Charts: A Word of Warning
I’m often asked why this site doesn’t have a lengthy merchant account comparison chart. The answer is simple – these intricate comparison charts are useless.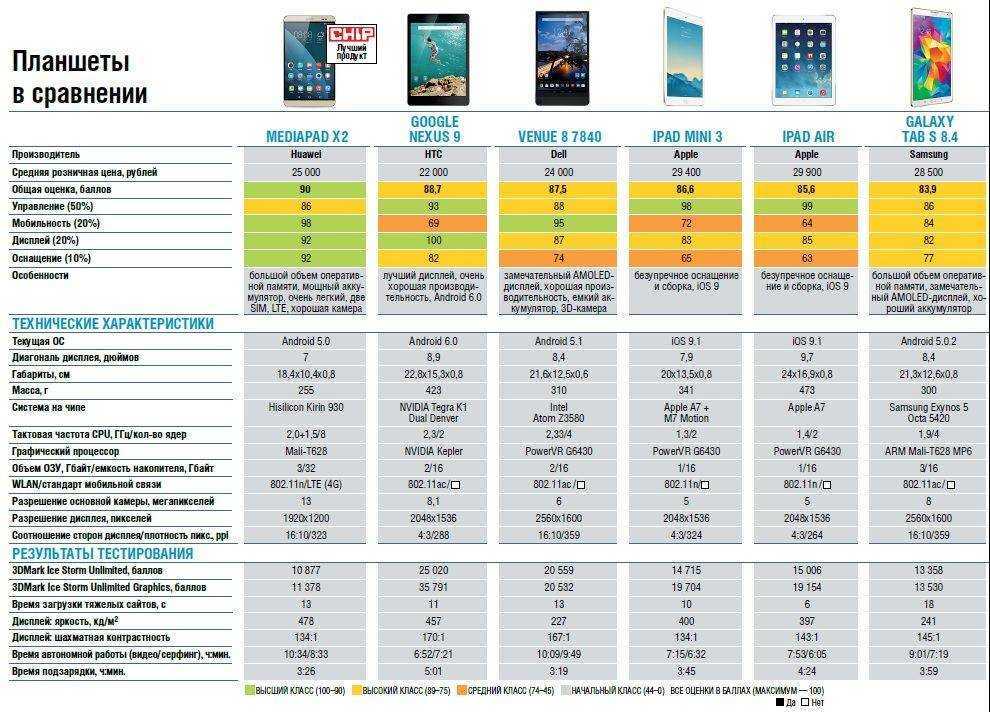
Charts are easily manipulated, leaving you to try comparing apples and oranges. Even if the creator of the chart doesn’t intend to mislead, a lack of complete information can be just as detrimental to finding the right solution. When you’re looking for the best credit card processor, the key is to find the right one for your specific business.
In this article, I’ll explain why merchant account comparison charts don’t provide the information you need, go over a real example, and show you how to truly compare apples to apples to find the best credit card processing.
- Credit Card Processing Comparison Chart Problems
- Comparison Charts Offer Biased Information
- Published Pricing Can Be Easily Manipulated
- Best Credit Card Processing Chart
- Business-Specific Variables
- How can I compare processors?
Credit Card Processing Comparison Chart Problems
Anyone that’s done research to find the best merchant account knows the charts that I’m referring to. They’re laid out as neatly constructed tables listing the rates and fees offered by different merchant service providers. In many cases, the charts compare rates for tiered pricing models, but interchange plus charts can be just as misleading.
They’re laid out as neatly constructed tables listing the rates and fees offered by different merchant service providers. In many cases, the charts compare rates for tiered pricing models, but interchange plus charts can be just as misleading.
There are two big problems with these charts that make them virtually useless. Firstly, they’re almost always provided by a company trying to get your business, so they’re extremely biased. To the processor, comparison charts are a sales tool, not an educational piece to help you.
Secondly, you can’t accurately compare merchant accounts from one provider to the next because pricing has no set terms to use as a basis for comparison. Without standardization, the charts are comparing apples and oranges.
Comparison Charts Offer Biased Information
The first obstacle to a useful rate comparison chart is that they’re often created and hosted by merchant account providers or their affiliates. Not surprisingly, the processor that hosts the chart always shows lower rates and fees than their competitors, but there’s no way to verify if that’s actually the rate you’ll pay. If you make a decision based on the rates in these charts, you could fall victim to credit card rate bait and switch tactics.
If you make a decision based on the rates in these charts, you could fall victim to credit card rate bait and switch tactics.
Published Pricing Can Be Easily Manipulated
Merchant account fees are inconsistent by nature and can change frequently. In fact, rates can change as often as twice a year when Visa and MasterCard adjust their interchange fees. So the rates you see published in a comparison chart can quickly become out of date.
On top of the frequency with which rates and fees change, the tremendous amount of competition in the payment card industry leaves pricing constantly in flux. Processors work to match or beat their competitors’ rates. This is especially true of providers who quote using tiered or bundled pricing, which can be easily manipulated by the provider.
Processors aren’t required to use a particular pricing structure, which means there are no standards that can be used as a basis for an accurate comparison chart. To try to beat the competition, sales reps might waive fees, change contract terms, or lower equipment prices to entice you to sign up with them. Even when you’re reviewing rates from one processor it’s possible to get different quotes from different sales representatives working for the same company. What you see in a rate comparison chart might not be what you get, making it impossible to choose based on comparison chart rate information.
Even when you’re reviewing rates from one processor it’s possible to get different quotes from different sales representatives working for the same company. What you see in a rate comparison chart might not be what you get, making it impossible to choose based on comparison chart rate information.
Processors who offer to pay cash if they can’t beat your current rates are a perfect example of how prices can be manipulated. They will always be able to “beat” your current rates by offering lower, but just because they’ve given you a lower rate doesn’t mean you actually pay less. The processor can decide that almost none of your transactions “qualify” for the lowest rate. So even though your processor quotes one low rate, they can charge the majority of your credit card sales at a much higher rate.
Related Article: The Truth Behind “$500 If We Can’t Beat Your Rates” Offers.
Processor-created and hosted charts aren’t the only comparison charts out there, though.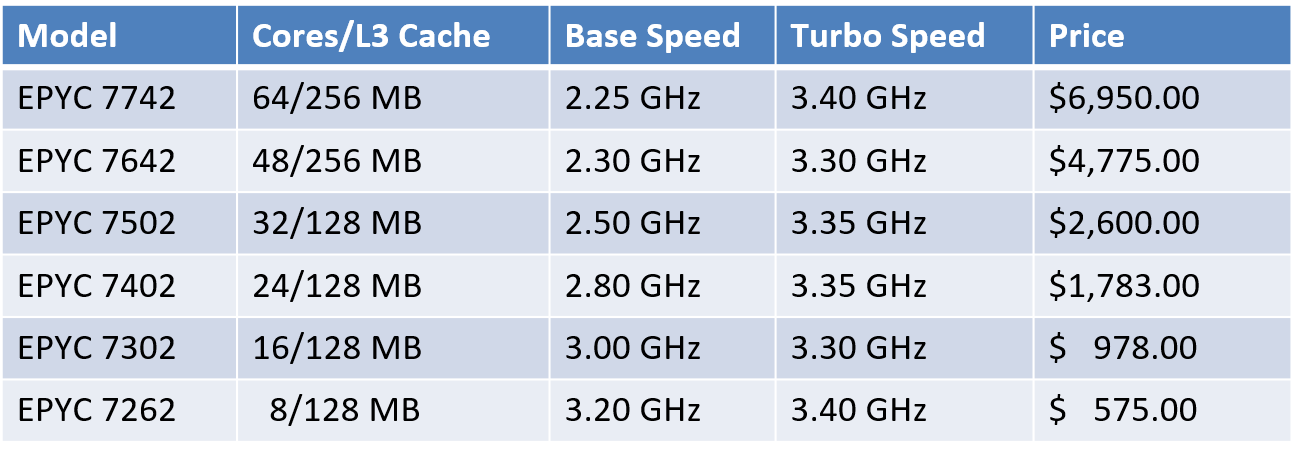 Independent review sites, business websites, and others may also post charts, attempting to help businesses compare solutions. As well-intentioned as these charts may be, they can still lead a business to the wrong conclusion. In the next section, we’ll look at one such chart.
Independent review sites, business websites, and others may also post charts, attempting to help businesses compare solutions. As well-intentioned as these charts may be, they can still lead a business to the wrong conclusion. In the next section, we’ll look at one such chart.
Best Credit Card Processing Chart
The screenshot below is a chart I came across on a business website in an article about finding the best credit card processing. As you can see, the chart lists 5 processors, specifying that each is best for a particular need: small business, high volume, low volume, mobile, and online.
The approach is commendable. After all, what’s best for an online business may not be what’s best for a mobile business.
But what the chart doesn’t mention is that the first two processors listed use a different pricing model than the last three. If you were to look at this chart with the goal of finding the lowest costs, you would see rates of 0.2 – 0.5% + 15 cents per transaction in the first box and rightfully conclude that that’s lower than 2. 9% + 30 cents per transaction in the last box. However, the chart fails to include the fact that the first box’s listed “rates” don’t include interchange – the biggest component of costs. The rate listed here is just one component – the processor’s markup. A business choosing the first processor will pay much more than 0.2 – 0.5% and may feel duped.
9% + 30 cents per transaction in the last box. However, the chart fails to include the fact that the first box’s listed “rates” don’t include interchange – the biggest component of costs. The rate listed here is just one component – the processor’s markup. A business choosing the first processor will pay much more than 0.2 – 0.5% and may feel duped.
For the “flat rate” style processing of the last two examples, the processor’s markup is bundled into the 2.9% + 30 cent rate, meaning there is no way to know what the markup portion is. In order for this chart to be helpful, you’d need to be able to compare just that markup to the 0.2 – 0.5% + 15 cents per transaction from the first box.
It’s important to understand not just “rates” but all the costs associated and the pricing model the processor uses.
Read more about Pricing Models.
Business-Specific Variables
In addition to the different pricing models mixed together in this chart, businesses won’t be able to take into account variables specific to their business. For example, while the chart states that the first processor is best for “small business overall” that won’t be accurate for many small businesses, especially ones looking for the lowest cost.
For example, while the chart states that the first processor is best for “small business overall” that won’t be accurate for many small businesses, especially ones looking for the lowest cost.
Many factors go into the cost to accept credit cards, including industry, average transaction size, monthly volume, and more. A business with an average transaction size under $10 will generally be better off going with a flat rate processor (one of the last three in the chart) rather than an interchange plus processor, meaning that coffee shops, food trucks, pizza parlors, and other quick-serve establishments could be easily misled by this chart, thinking that they should choose “best for small business overall” because they aren’t looking for mobile, online, or low volume processing. However, doing so would likely result in higher costs than necessary.
The reason a business with transactions under $10 would typically pay less with flat rate processing is due to the costs involved in processing small transactions. Credit card processors have to pay banks and the credit card companies for every transaction they process. Flat rate processors may actually lose money, which is what happened when Square processed cards for Starbucks.
Credit card processors have to pay banks and the credit card companies for every transaction they process. Flat rate processors may actually lose money, which is what happened when Square processed cards for Starbucks.
Static charts can’t know how these factors will play into your business, and therefore can only provide very rough guidelines that can just as easily lead you to the wrong conclusion.
For example…
As another example, an online business might think that they should go with the “best for online” processor, not taking into account how quickly a 30 cent per-transaction fee can add up. If the business processes a lot of transactions, it would make more sense to choose a processor with a lower per-transaction fee.
In other words, if you have to pay 30 cents for each transaction, that will result in very different costs if you have one hundred $50 transactions or if you have ten $500 transactions. With one hundred transactions, you’re paying $30 in just per-transaction fees. With 10 transactions, you’re paying $3. It could be a good choice for the business with a few higher value transactions, but may not be for the business with lots of transactions. By contrast, the “best for small business overall” processor is shown offering 15 cents per transaction, or half of the amount of the “best online” processor. On one hundred transactions, you’d save $15 in transaction fees going with them instead of the “best for online” processor in the chart.
With 10 transactions, you’re paying $3. It could be a good choice for the business with a few higher value transactions, but may not be for the business with lots of transactions. By contrast, the “best for small business overall” processor is shown offering 15 cents per transaction, or half of the amount of the “best online” processor. On one hundred transactions, you’d save $15 in transaction fees going with them instead of the “best for online” processor in the chart.
Charts can’t effectively communicate these business-specific variables, which can result in expensive mistakes by choosing the wrong processor.
At this point, you may be thinking that there’s no good or effective way to compare processors. It seems like every rule has a caveat and it’s enough to make your head spin. Fortunately, there are easier and more reliable ways to compare processors to truly find the best credit card processing.
How can I compare processors?
Rather than using a misleading or out-of-date comparison chart, the best solution for comparing processors is to obtain accurate pricing information that uses one pricing model (preferably interchange plus) and compare offers yourself. You’ll need to be able to see the markup over cost, not just teaser “rates.”
You’ll need to be able to see the markup over cost, not just teaser “rates.”
You can obtain this information by calling processors to request quotes and attempting to get all the information and fees disclosed in writing, but it’s easier to use a dynamic comparison tool like the one offered here at CardFellow. Our price comparison tool lets you put in your business transaction details so that you’ll get accurate, personalized quotes instead of teaser rates or generic pricing.
Give it a shot. You can sign up for free to get personalized quotes from multiple merchant account providers. All of the providers in CardFellow’s marketplace are required to offer quotes using interchange plus pricing structures, allowing us to ensure a standard for an apples-to-apples comparison that you can actually use. There’s no obligation, and we never share your contact info.
Whether you choose to do the research yourself or use an impartial website like CardFellow, don’t be fooled by misleading, biased merchant account comparison charts floating around the internet. You’re not looking for the best credit card processor by some arbitrary measure or limited to the processors the chart-maker decides you should consider. You’re looking for the best credit card processing solution for you. Charts aimed at the general business world don’t offer the level of advice and insight you need. Skip them and save yourself the hassle.
You’re not looking for the best credit card processor by some arbitrary measure or limited to the processors the chart-maker decides you should consider. You’re looking for the best credit card processing solution for you. Charts aimed at the general business world don’t offer the level of advice and insight you need. Skip them and save yourself the hassle.
Introduction to Parallel Computing / Sudo Null IT News
Roughly speaking, a set of processors, memory and some methods of communication between them is called a parallel machine. It can be a dual-core processor in your (no longer new) laptop, a multi-processor server, or, for example, a cluster (supercomputer). You may not know anything about these computers, but you know exactly why they are built: speed, speed, and more speed. However, speed is not the only advantage.
After completing the not-so-trivial task of creating such a device, designers and developers still have to think about how to make it work. After all, the techniques and algorithms used for old, single-processor, single-threaded machines, as a rule, are not suitable. nine0003
After all, the techniques and algorithms used for old, single-processor, single-threaded machines, as a rule, are not suitable. nine0003
What is most surprising is that universities are not yet in a hurry to transfer their training programs to the mainstream of parallel computing! At the same time, today you need to try to find a computer with one core. At my hometown Carleton University, courses in parallel computing are not part of the required Bachelor of Computer Science program, and are only available to those who have completed the core courses of the first three years. At the same level are courses in distributed computing, and some can be confusing. nine0003
What’s the difference? Parallel computing involves equipment located, as a rule, in one physical place, they are closely interconnected and all the parameters of their work are known to the programmer. In distributed computing, there is no close permanent connection between the nodes, according to the name, they are distributed over a certain territory and the operating parameters of this system are dynamic and not always known.
Classical algorithms that have been taught for the last half century are no longer suitable for parallel systems. As you might guess, an algorithm for a parallel machine is called a parallel algorithm. It often depends heavily on the architecture of a particular machine and is not as versatile as its classic ancestor. nine0003
You might ask: why was it necessary to come up with a new structure, then tinker with new algorithms, and was it not possible to continue speeding up ordinary computers? First, it is not yet possible to make a single super-fast processor that can be compared to today’s parallel supercomputers; and if there is, then a lot of resources will be spent on it. In addition, many problems are well solved by parallel machines primarily due to such a structure! Calculation of complex chaotic systems like weather, simulation of interactions of elementary particles in physics, modeling at the nano-level (yes, yes, nanotechnology!), data mining (about which we have a blog on the site), cryptography… the list goes on and on. nine0013
nine0013
For a programmer, as the end “user” of a parallel machine, two options are possible: parallelism can be “visible” to him, or not. In the first case, the programmer writes programs based on the architecture of the computer, taking into account the parameters of this particular machine. In the second, the programmer may not know that he is facing a non-classical computer, and all his classical methods manage to work thanks to the thoughtfulness of the system itself.
Here is an example of a multi-core processor — loved by many SUN UltraSPARC T1/T2:
8 cores, each supporting 4 (for T1) or 8 (for T2) hardware threads (thread), which by simple multiplication gives us 32/64 (respectively) threads in the processor. Theoretically, this means that such a processor can perform 32/64 tasks of a single-threaded processor in the same time. But, of course, a lot of resources are spent on switching between threads and other “inner kitchen”.
And here, for example, are the famous coolest graphics units like the nVidia GeForce 9600 GT, which has 64 cores on board. nine0003
nine0003
The latest GPUs have up to a thousand cores! We will talk about why graphics units have so many cores a little later. And now look better at the example of the hierarchy of parallelism in supercomputers:
It is clear that getting a bunch of powerful computers is not a problem. The problem is to make them work together, that is, to connect them into a fast network. Often in such clusters a high-speed switch is used and all computers are simply connected to a fast local network. Here is one, for example, in our university:
256 cores: 64 units, each with 4 cores of 2.2 GHz and 8 gigabytes of RAM. The connection uses a Foundry SuperX switch and a gigabit network. OS: Linux Rocks. The most expensive element is often the switch: try to find a fast 64-port switch! This is an example of one of the biggest problems with parallel computers: the speed of information exchange. Processors have become very fast, while memory and buses are still slow. Not to mention hard drives — compared to processors, they look like tools from the stone age! nine0003
Not to mention hard drives — compared to processors, they look like tools from the stone age! nine0003
Classification
Let’s finally understand the types of parallel machines. They differ in the type of memory — shared (shared) or distributed (distributed), and in the type of management — SIMD and MIMD. It turns out that there are four types of parallel machines.
Shared memory
A classic computer looks like this:
And the most obvious way to expand this scheme to include multiple processors is: It turns out that all processors share a common memory, and if processor 2 needs some information that processor 3 is working on, then it will receive it from the shared memory at the same speed. nine0003
This is what a Quad Pentium built according to this scheme looks like:
Distributed memory
As you probably guessed, in this case each processor has “its own” memory (I remind you that we are not talking about the internal memory of the processor).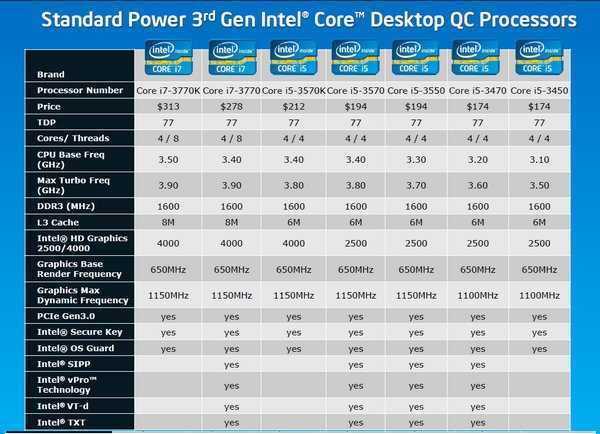
An example is the cluster described above: it is essentially a bunch of separate computers, each of which has its own memory. In this case, if processor (or computer) 2 needs information from computer 3, then it will take longer: it will need to request information and transfer it (in the case of a cluster, over a local network). The topology of the network will affect the speed of information exchange, so different types of structures have been developed. nine0003
The simplest option that comes to mind is a simple two-dimensional array (mesh):
Or a cube:
IBM Blue Gene, a descendant of the famous IBM Deep Blue, who beat a man at chess, has a similar structure. Similar, because in fact Blue Gene is not a cube, but a torus — the extreme elements are connected:
By the way, it was called Gene, because it is actively used in genetic research.
Another interesting structure that must have crossed someone’s mind is the beloved tree:
Since the depth (or height) of a binary tree is logn, the transfer of information from the two most distant nodes will travel a distance of 2*logn, which is very good, but this structure is still not used often. First, to divide such a network into two isolated subnets, it is enough to cut one wire (remember the min-cut problem?) In the case of a two-dimensional array, you need to cut sqrt(n) wires! Do the math for the cube. And secondly, there is too much traffic going through the root node! nine0003
First, to divide such a network into two isolated subnets, it is enough to cut one wire (remember the min-cut problem?) In the case of a two-dimensional array, you need to cut sqrt(n) wires! Do the math for the cube. And secondly, there is too much traffic going through the root node! nine0003
Four-dimensional hypercubes were popular in the 80s:
These are two three-dimensional cubes with the corresponding vertices connected. They built cubes of even greater dimensions, but now they are almost never used, also because it is a huge amount of wires!
In general, network design for solving some problem is an interesting topic. Here, for example, the so-called Omega Network:
We figured out the memory, now about the management.
SIMD vs. MIMD
SIMD — Singe Instruction stream, Multiple Data stream. There is only one control node, it sends instructions to all other processors. Each processor has its own set of data to work with.
MIMD — Multiple Instruction Stream, Multiple Data Stream. Each processor has its own control unit, each processor can execute different instructions.
SIMD systems are usually used for specific tasks that require, as a rule, not so much the flexibility and versatility of a computer, but the computing power itself. Media processing, scientific research (the same simulations and simulations), or, for example, Fourier transforms of giant matrices. That is why graphics units have such a crazy number of cores: these are SIMD systems, and there is usually only one truly “smart” processor (such as in your computer): it controls a bunch of simple and non-universal cores. nine0003
Since the “control” processor sends the same instructions to all “worker” processors, programming such systems requires some skill. Here is a simple example:
if (B == 0)
then C = A
else C = A/B
The initial state of the processor memory is as follows:
The first line was executed, the data was read, now the second line is started: then
At the same time, the second and third processors do nothing, because the variable B does not fit the condition. Accordingly, the third line is then executed, and this time the other two processors “rest”:
Accordingly, the third line is then executed, and this time the other two processors “rest”:
Examples of SIMD machines are the old ILLiac IV, MPP, DAP, Connection Machine CM-1/2, modern vector units, specific coprocessors, and graphics units like the nVidia GPU.
MIMD machines have more functionality, which is why our user computers use them. If you have at least a dual-core processor in your laptop, you are the lucky owner of a MIMD machine with shared memory! Distributed memory MIMDs are supercomputers like the IBM Blue Gene we talked about above, or clusters. nine0003
Here is the summary of the entire classification:
This introduction to the topic can be considered complete. Next time we will talk about how the speeds of parallel machines are calculated, write our first parallel program using recursion, run it in a small cluster and learn how to analyze its speed and resource consumption.
Main classes of modern parallel computers | PARALLEL.
 RU
RU
MPP,
SMP,
numa,
pvp,
clusters.
Introduction .
The main parameter of the classification of parallel computers
is the presence of a common
(SMP) or distributed memory (MPP).
Something in between SMP and MPP are
NUMA architectures,
where the memory is physically allocated but logically shared.
Cluster
systems are a cheaper option for MPP.
With the support of vector data processing commands, one speaks of vector-pipeline
processors, which, in turn, can be combined into
PVP systems
using shared or distributed memory.
Combination ideas are becoming more and more popular.
different architectures in one system and building heterogeneous systems.
nine0003
When organizing distributed computing in global networks
(Internet) talk about
meta-computers, which, strictly speaking,
are not parallel architectures.
In more detail, the features of all the listed architectures will be considered
later on this page, as well as in the descriptions of specific computers
representatives of these classes.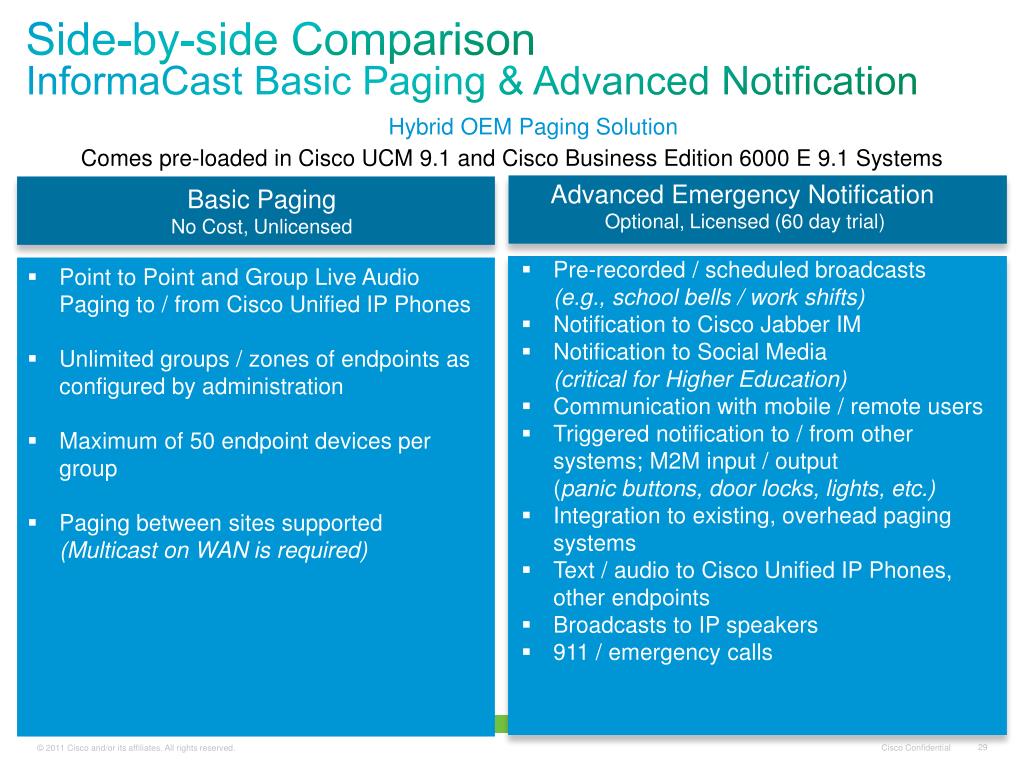
For each class, the following information is provided:
- brief description of the architectural features,
- examples of specific computers,
- scalability perspective,
- typical features of the construction of operating systems,
- the most typical programming model (although others are possible).
Note .
This page discusses the most typical classes of architectures
modern parallel computers and supercomputers.
(not considered
obsolete
and designed architectures.)
Massively Parallel (MPP)
| Architecture |
The system consists of homogeneous computing nodes ,
Special units can be added to the system |
|---|---|
| Examples |
IBM RS/6000 SP2, Intel PARAGON/ASCI Red, CRAY t3e, Hitachi SR8000, Parsytec transputer systems. |
| Scalable | The total number of processors in real systems reaches several thousand (ASCI Red, Blue Mountain). |
| Operating system |
There are two main options:
|
| Programming model | Model programming messaging ( MPI, pvm, BSPlib) |
Additional information:
- Lecture on the architecture of massively parallel
computers, on the example of CRAY T3D (Vl. V.Voevodin).
V.Voevodin).
nine0148 - Distributed memory parallel computers
(article in ComputerWorld, #22, 1999) - An Overview of the Intel TFLOPS Supercomputer
Symmetrical Multiprocessor (SMP) systems
| Architecture | The system consists of several homogeneous processors and a shared memory array (usually from several independent blocks). All processors access any point in memory at the same speed. Processors connected to memory either using a common bus (basic 2-4 processor SMP servers), or using crossbar switch (HP 9000). Hardware-assisted cache coherence. |
|---|---|
| Examples | HP 9000 V-class, N-class; SMP servers and workstations based on Intel processors (IBM, HP, Compaq, Dell, ALR, Unisys, DG, Fujitsu, etc.). |
| Scalability |
Availability of shared memory greatly simplifies the interaction of processors with each other, however imposes strong restrictions on their number — no more than 32 in real systems.  To build scalable systems based on SMP, we use To build scalable systems based on SMP, we usecluster or NUMA architectures. nine0186 |
| Operating system |
The entire system runs under a single OS (usually UNIX-like, but Windows NT is supported for Intel platforms). OS automatically (during operation) distributes processes/threads across processors (scheduling), but sometimes explicit binding is also possible. |
| Programming Model | Model programming shared memory . (POSIX threads, OpenMP). For SMP systems, there are relatively effective tools automatic parallelization. nine0186 |
Non-uniform memory access (NUMA) systems
| Architecture | The system consists of homogeneous basic modules (boards), consisting of a small number of processors and a block of memory. The modules are connected using a high-speed switch. Supports a single address space hardware supported access to remote memory, those.  to the memory of other modules. to the memory of other modules.At the same time, access to local memory several times faster than remote. nine0004 If the hardware supports cache coherence throughout the system (usually this is the case), talking about architecture cc-NUMA (cache-coherent NUMA) |
|---|---|
| Examples |
HP HP 9000 V-class in SCA configurations, SGI Origin2000, Sun HPC 10000, IBM/Sequent NUMA-Q 2000, SNI RM600. |
| Scalability |
The scalability of NUMA systems is limited by the volume address space, hardware capabilities to support cache coherency, and the ability of the operating system to manage a large number of processors. Currently, the maximum number of processors in NUMA systems is 256 (Origin2000). nine0186 |
| Operating system |
Usually the entire system runs under a single OS, as in SMP. But it is also possible options for dynamic «subdivision» of the system, when separate «partitions» systems run on different operating systems (for example, Windows NT and UNIX in NUMA-Q 2000). 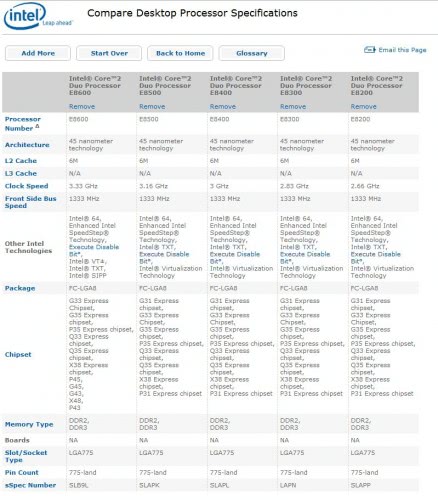
|
| Programming Model | Similar to SMP. |
Parallel Vector Systems (PVP)
|
Architecture nine0168 | The main feature of PVP systems is the presence of special vector-pipeline processors, which provide commands for the same type of vector processing independent data, efficiently executed on conveyor belts functional devices. Typically, several of these processors (1-16) |
|---|---|
| Examples | NEC SX-4/SX-5 Line of Vector Pipeline Computers CRAY: from CRAY-1, CRAY J90/T90, CRAY SV1, Cray X1, Fujitsu VPP series. |
| Programming Model | Efficient programming involves loop vectorization (for achieve reasonable performance on a single processor) and their parallelization (for simultaneous loading of several processors with one application). 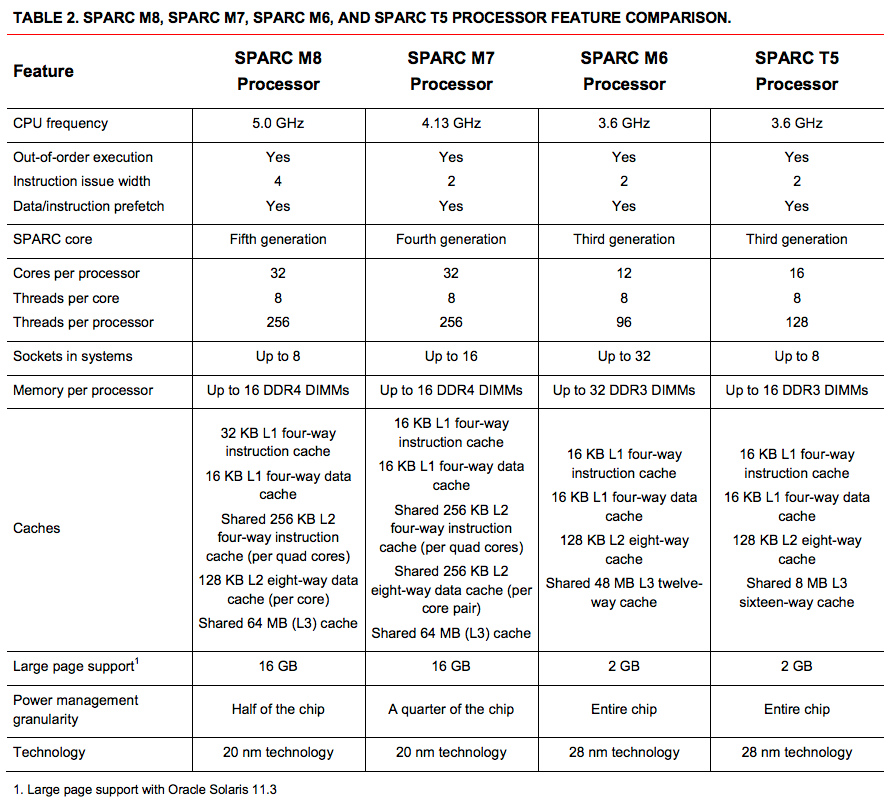
|
Additional information:
nine0003
- Lecture on the architecture of vector-pipeline supercomputers CRAY C90.
(Vl.V.Voevodin)
Cluster systems
| Architecture |
A set of workstations (or even PCs) for general purposes, used as a cheap option massively parallel computer. Used to connect nodes one of the standard network technologies (Fast/Gigabit Ethernet, Myrinet) based on bus architecture or switch. When clustering computers of different capacities Cluster nodes can be used simultaneously |
|---|---|
| Examples |
NT cluster in NCSA, Beowulf clusters. |
| Operating system |
Uses standard operating systems for workstations, most often freely distributed — Linux / FreeBSD, together with special tools to support parallel programming and load distribution. 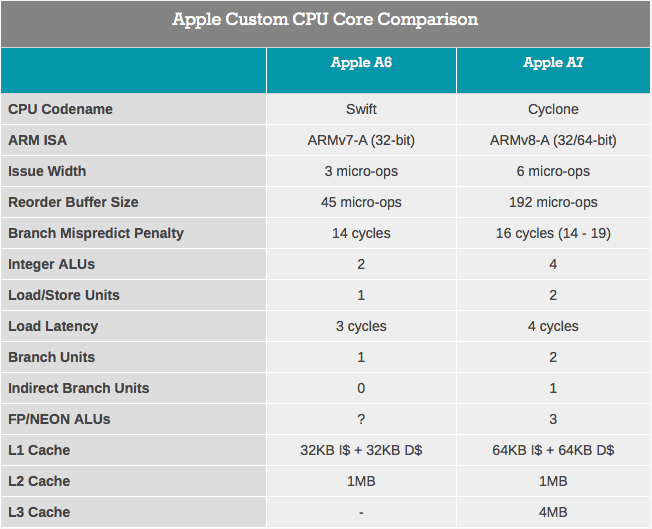
|