Stable Diffusion Benchmarked: Which GPU Runs AI Fastest (Updated)
When you purchase through links on our site, we may earn an affiliate commission. Here’s how it works.
(Image credit: Tom’s Hardware)
Artificial Intelligence and deep learning are constantly in the headlines these days, whether it be ChatGPT generating poor advice, self-driving cars, artists being accused of using AI, medical advice from AI, and more. Most of these tools rely on complex servers with lots of hardware for training, but using the trained network via inference can be done on your PC, using its graphics card. But how fast are consumer GPUs for doing AI inference?
We’ve benchmarked Stable Diffusion, a popular AI image creator, on the latest Nvidia, AMD, and even Intel GPUs to see how they stack up. If you’ve by chance tried to get Stable Diffusion up and running on your own PC, you may have some inkling of how complex — or simple! — that can be. The short summary is that Nvidia’s GPUs rule the roost, with most software designed using CUDA and other Nvidia toolsets. But that doesn’t mean you can’t get Stable Diffusion running on the other GPUs.
We ended up using three different Stable Diffusion projects for our testing, mostly because no single package worked on every GPU. For Nvidia, we opted for Automatic 1111’s webui version; it performed best, had more options, and was easy to get running. AMD GPUs were tested using Nod.ai’s Shark version — we checked performance on Nvidia GPUs (in both Vulkan and CUDA modes) and found it was… lacking. Getting Intel’s Arc GPUs running was a bit more difficult, due to lack of support, but Stable Diffusion OpenVINO gave us some very basic functionality.
Disclaimers are in order. We didn’t code any of these tools, but we did look for stuff that was easy to get running (under Windows) that also seemed to be reasonably optimized. We’re relatively confident that the Nvidia 30-series tests do a good job of extracting close to optimal performance — particularly when xformers is enabled, which provides an additional ~20% boost in performance (though at reduced precision that may affect quality). RTX 40-series results meanwhile were lower initially, but George SV8ARJ provided this fix, where replacing the PyTorch CUDA DLLs gave a healthy boost to performance.
RTX 40-series results meanwhile were lower initially, but George SV8ARJ provided this fix, where replacing the PyTorch CUDA DLLs gave a healthy boost to performance.
The AMD results are also a bit of a mixed bag: RDNA 3 GPUs perform very well while the RDNA 2 GPUs seem rather mediocre. Nod.ai let us know they’re still working on ‘tuned’ models for RDNA 2, which should boost performance quite a bit (potentially double) once they’re available. Finally, on Intel GPUs, even though the ultimate performance seems to line up decently with the AMD options, in practice the time to render is substantially longer — it takes 5–10 seconds before the actual generation task kicks off, and probably a lot of extra background stuff is happening that slows it down.
We’re also using different Stable Diffusion models, due to the choice of software projects. Nod.ai’s Shark version uses SD2.1, while Automatic 1111 and OpenVINO use SD1.4 (though it’s possible to enable SD2.1 on Automatic 1111). Again, if you have some inside knowledge of Stable Diffusion and want to recommend different open source projects that may run better than what we used, let us know in the comments (or just email Jarred).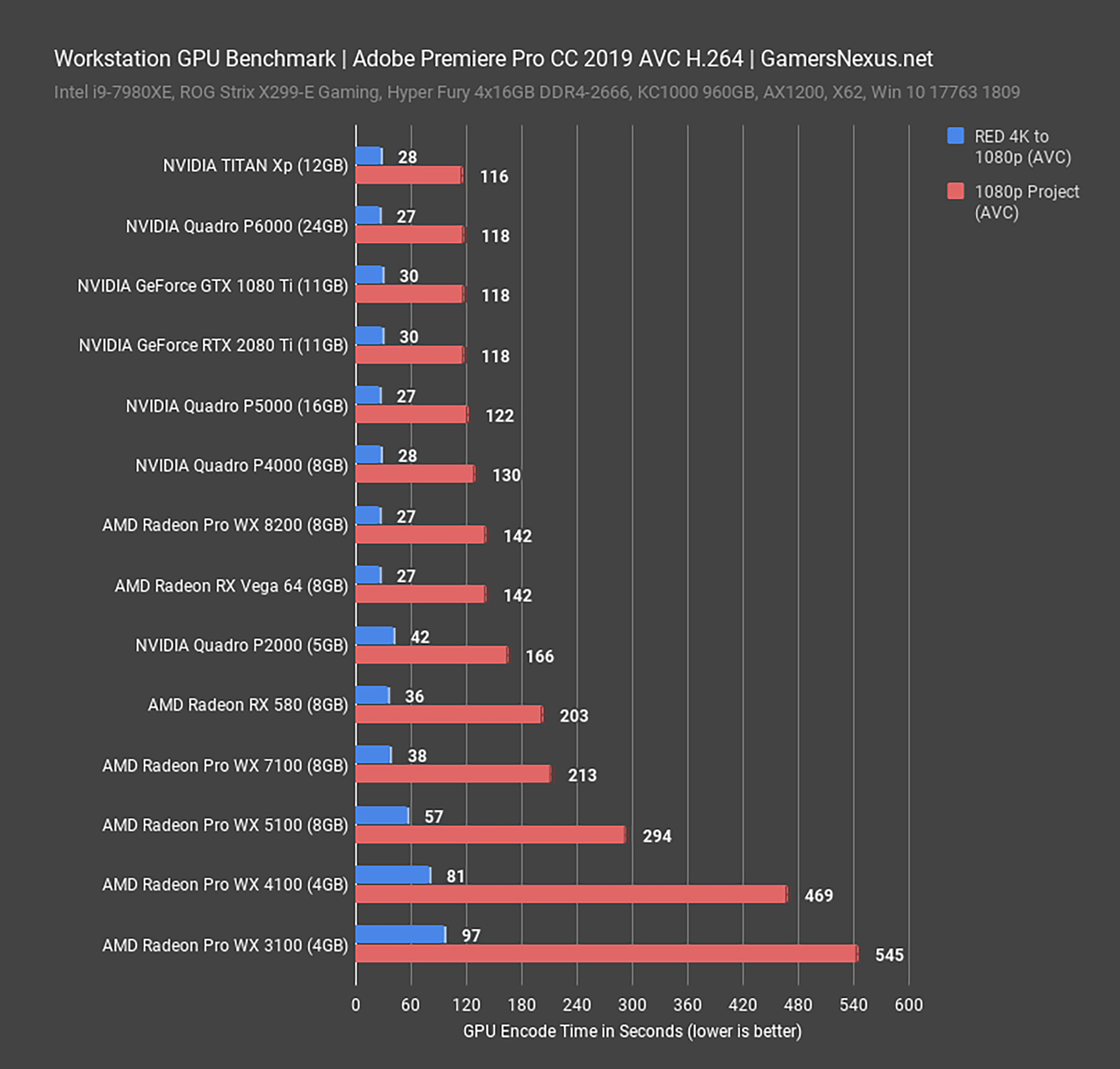
Image 1 of 11
(Image credit: Tom’s Hardware)(Image credit: Tom’s Hardware)(Image credit: Tom’s Hardware)(Image credit: Tom’s Hardware)(Image credit: Tom’s Hardware)(Image credit: Tom’s Hardware)(Image credit: Tom’s Hardware)(Image credit: Tom’s Hardware)(Image credit: Tom’s Hardware)(Image credit: Tom’s Hardware)(Image credit: Tom’s Hardware)
Our testing parameters are the same for all GPUs, though there’s no option for a negative prompt option on the Intel version (at least, not that we could find). The above gallery was generated using Automatic 1111’s webui on Nvidia GPUs, with higher resolution outputs (that take much, much longer to complete). It’s the same prompts but targeting 2048×1152 instead of the 512×512 we used for our benchmarks. Note that the settings we chose were selected to work on all three SD projects; some options that can improve throughput are only available on Automatic 1111’s build, but more on that later. Here are the pertinent settings:
Positive Prompt:
postapocalyptic steampunk city, exploration, cinematic, realistic, hyper detailed, photorealistic maximum detail, volumetric light, (((focus))), wide-angle, (((brightly lit))), (((vegetation))), lightning, vines, destruction, devastation, wartorn, ruins
Negative Prompt:
(((blurry))), ((foggy)), (((dark))), ((monochrome)), sun, (((depth of field)))
Steps:
100
Classifier Free Guidance:
15. 0
0
Sampling Algorithm:
Some Euler variant (Ancestral on Automatic 1111, Shark Euler Discrete on AMD)
The sampling algorithm doesn’t appear to majorly affect performance, though it can affect the output. Automatic 1111 provides the most options, while the Intel OpenVINO build doesn’t give you any choice.
Here are the results from our testing of the AMD RX 7000/6000-series, Nvidia RTX 40/30-series, and Intel Arc A-series GPUs. Note that each Nvidia GPU has two results, one using the default computational model (slower and in black) and a second using the faster «xformers» library from Facebook (faster and in green).
(Image credit: Tom’s Hardware)
As expected, Nvidia’s GPUs deliver superior performance — sometimes by massive margins — compared to anything from AMD or Intel. With the DLL fix for Torch in place, the RTX 4090 delivers 50% more performance than the RTX 3090 Ti with xformers, and 43% better performance without xformers. It takes just over three seconds to generate each image, and even the RTX 4070 Ti is able to squeak past the 3090 Ti (but not if you disable xformers).
Things fall off in a pretty consistent fashion from the top cards for Nvidia GPUs, from the 3090 down to the 3050. Meanwhile, AMD’s RX 7900 XTX ties the RTX 3090 Ti (after additional retesting) while the RX 7900 XT ties the RTX 3080 Ti. The 7900 cards look quite good, while every RTX 30-series card ends up beating AMD’s RX 6000-series parts (for now). Finally, the Intel Arc GPUs come in nearly last, with only the A770 managing to outpace the RX 6600. Let’s talk a bit more about the discrepancies.
Proper optimizations could double the performance on the RX 6000-series cards. Nod.ai says it should have tuned models for RDNA 2 in the coming days, at which point the overall standing should start to correlate better with the theoretical performance. Speaking of Nod.ai, we also did some testing of some Nvidia GPUs using that project, and with the Vulkan models the Nvidia cards were substantially slower than with Automatic 1111’s build (15.52 it/s on the 4090, 13.31 on the 4080, 11. 41 on the 3090 Ti, and 10.76 on the 3090 — we couldn’t test the other cards as they need to be enabled first).
41 on the 3090 Ti, and 10.76 on the 3090 — we couldn’t test the other cards as they need to be enabled first).
Based on the performance of the 7900 cards using tuned models, we’re also curious about the Nvidia cards and how much they’re able to benefit from their Tensor cores. On paper, the 4090 has over five times the performance of the RX 7900 XTX — and 2.7 times the performance even if we discount scarcity. In practice, the 4090 right now is only about 50% faster than the XTX with the versions we used (and that drops to just 13% if we omit the lower accuracy xformers result). That same logic also applies to Intel’s Arc cards.
Intel’s Arc GPUs currently deliver very disappointing results, especially since they support FP16 XMX (matrix) operations that should deliver up to 4X the throughput as regular FP32 computations. We suspect the current Stable Diffusion OpenVINO project that we used also leaves a lot of room for improvement. Incidentally, if you want to try and run SD on an Arc GPU, note that you have to edit the ‘stable_diffusion_engine. py’ file and change «CPU» to «GPU» — otherwise it won’t use the graphics cards for the calculations and takes substantially longer.
py’ file and change «CPU» to «GPU» — otherwise it won’t use the graphics cards for the calculations and takes substantially longer.
Overall then, using the specified versions, Nvidia’s RTX 40-series cards are the fastest choice, followed by the 7900 cards, and then the RTX 30-series GPUs. The RX 6000-series underperforms, and Arc GPUs look generally poor. Things could change radically with updated software, and given the popularity of AI we expect it’s only a matter of time before we see better tuning (or find the right project that’s already tuned to deliver better performance).
(Image credit: Tom’s Hardware)
We also ran some tests on legacy GPUs, specifically Nvidia’s Turing architecture (RTX 20- and GTX 16-series) and AMD’s RX 5000-series. The RX 5600 XT failed so we left off with testing at the RX 5700, and the GTX 1660 Super was slow enough that we felt no need to do any further testing of lower tier parts. But the results here are quite interesting.
First, the RTX 2080 Ti ends up outperforming the RTX 3070 Ti. That doesn’t normally happen, and in games even the vanilla 3070 tends to beat the former champion. More importantly, these numbers suggest that Nvidia’s «sparsity» optimizations in the Ampere architecture aren’t being used at all — or perhaps they’re simply not applicable.
That doesn’t normally happen, and in games even the vanilla 3070 tends to beat the former champion. More importantly, these numbers suggest that Nvidia’s «sparsity» optimizations in the Ampere architecture aren’t being used at all — or perhaps they’re simply not applicable.
We’ll get to some other theoretical computational performance numbers in a moment, but again consider the RTX 2080 Ti and RTX 3070 Ti as an example. The 2080 Ti Tensor cores don’t support sparsity and have up to 108 TFLOPS of FP16 compute. The RTX 3070 Ti supports sparsity with 174 TFLOPS of FP16, or 87 TFLOPS FP16 without sparsity. The fact that the 2080 Ti beats the 3070 Ti clearly indicates sparsity isn’t a factor. The same logic applies to other comparisons like 2060 and 3050, or 2070 Super and 3060 Ti.
As for AMD’s RDNA cards, the RX 5700 XT and 5700, there’s a wide gap in performance. The 5700 XT lands just ahead of the 6650 XT, but the 5700 lands below the 6600. On paper, the XT card should be up to 22% faster. In our testing, however, it’s 37% faster. Either way, neither of the older Navi 10 GPUs are particularly performant in our initial Stable Diffusion benchmarks.
In our testing, however, it’s 37% faster. Either way, neither of the older Navi 10 GPUs are particularly performant in our initial Stable Diffusion benchmarks.
Finally, the GTX 1660 Super on paper should be about 1/5 the theoretical performance of the RTX 2060, using Tensor cores on the latter. If we use shader performance with FP16 (Turing has double the throughput on FP16 shader code), the gap narrows to just a 22% deficit. But in our testing, the GTX 1660 Super is only about 1/10 the speed of the RTX 2060.
Again, it’s not clear exactly how optimized any of these projects are. It’s also not clear if these projects are fully leveraging things like Nvidia’s Tensor cores or Intel’s XMX cores. As such, we thought it would be interesting to look at the maximum theoretical performance (TFLOPS) from the various GPUs. The following chart shows the theoretical FP16 performance for each GPU (only looking at the more recent graphics cards), using tensor/matrix cores where applicable. Nvidia’s results also include scarcity — basically the ability to skip multiplications by 0 for up to half the cells in a matrix, which is supposedly a pretty frequent occurrence with deep learning workloads.
Nvidia’s results also include scarcity — basically the ability to skip multiplications by 0 for up to half the cells in a matrix, which is supposedly a pretty frequent occurrence with deep learning workloads.
(Image credit: Tom’s Hardware)
Those Tensor cores on Nvidia clearly pack a punch (the grey/black bars are without sparsity), and obviously our Stable Diffusion testing doesn’t match up exactly with these figures — not even close. For example, on paper the RTX 4090 (using FP16) is up to 106% faster than the RTX 3090 Ti, while in our tests it was 43% faster without xformers, and 50% faster with xformers. Note also that we’re assuming the Stable Diffusion project we used (Automatic 1111) doesn’t leverage the new FP8 instructions on Ada Lovelace GPUs, which could potentially double the performance on RTX 40-series again.
Meanwhile, look at the Arc GPUs. Their matrix cores should provide similar performance to the RTX 3060 Ti and RX 7900 XTX, give or take, with the A380 down around the RX 6800. In practice, Arc GPUs are nowhere near those marks. The fastest A770 GPUs land between the RX 6600 and RX 6600 XT, the A750 falls just behind the RX 6600, and the A380 is about one fourth the speed of the A750. So they’re all about a quarter of the expected performance, which would make sense if the XMX cores aren’t being used.
In practice, Arc GPUs are nowhere near those marks. The fastest A770 GPUs land between the RX 6600 and RX 6600 XT, the A750 falls just behind the RX 6600, and the A380 is about one fourth the speed of the A750. So they’re all about a quarter of the expected performance, which would make sense if the XMX cores aren’t being used.
The internal ratios on Arc do look about right, though. Theoretical compute performance on the A380 is about one-fourth the A750, and that’s where it lands in terms of Stable Diffusion performance right now. Most likely, the Arc GPUs are using shaders for the computations, in full precision FP32 mode, and missing out on some additional optimizations.
The other thing to notice is that theoretical compute on AMD’s RX 7900 XTX/XT improved a lot compared to the RX 6000-series. We’ll have to see if the tuned 6000-series models closes the gaps, as Nod.ai said it expects about a 2X improvement in performance on RDNA 2. Memory bandwidth wasn’t a critical factor, at least for the 512×512 target resolution we used — the 3080 10GB and 12GB models land relatively close together.
(Image credit: Tom’s Hardware)
Here’s a different look at theoretical FP16 performance, this time focusing only on what the various GPUs can do via shader computations. Nvidia’s Ampere and Ada architectures run FP16 at the same speed as FP32, as the assumption is FP16 can be coded to use the Tensor cores. AMD and Intel GPUs in contrast have double performance on FP16 shader calculations compared to FP32.
Clearly, this second look at FP16 compute doesn’t match our actual performance any better than the chart with Tensor and Matrix cores, but perhaps there’s additional complexity in setting up the matrix calculations and so full performance requires… something extra. Which brings us to one last chart.
(Image credit: Tom’s Hardware)
This final chart shows the results of our higher resolution testing. We didn’t test the new AMD GPUs, as we had to use Linux on the AMD RX 6000-series cards, and apparently the RX 7000-series needs a newer Linux kernel and we couldn’t get it working. But check out the RTX 40-series results, with the Torch DLLs replaced.
But check out the RTX 40-series results, with the Torch DLLs replaced.
The RTX 4090 is now 72% faster than the 3090 Ti without xformers, and a whopping 134% faster with xformers. The 4080 also beats the 3090 Ti by 55%/18% with/without xformers. The 4070 Ti interestingly was 22% slower than the 3090 Ti without xformers, but 20% faster with xformers.
It looks like the more complex target resolution of 2048×1152 starts to take better advantage of the potential compute resources, and perhaps the longer run times mean the Tensor cores can fully flex their muscle.
Ultimately, this is at best a snapshot in time of Stable Diffusion performance. We’re seeing frequent project updates, support for different training libraries, and more. We’ll see about revisiting this topic more in the coming year, hopefully with better optimized code for all the various GPUs.
Join the experts who read Tom’s Hardware for the inside track on enthusiast PC tech news — and have for over 25 years. We’ll send breaking news and in-depth reviews of CPUs, GPUs, AI, maker hardware and more straight to your inbox.
We’ll send breaking news and in-depth reviews of CPUs, GPUs, AI, maker hardware and more straight to your inbox.
Contact me with news and offers from other Future brandsReceive email from us on behalf of our trusted partners or sponsors
Jarred Walton is a senior editor at Tom’s Hardware focusing on everything GPU. He has been working as a tech journalist since 2004, writing for AnandTech, Maximum PC, and PC Gamer. From the first S3 Virge ‘3D decelerators’ to today’s GPUs, Jarred keeps up with all the latest graphics trends and is the one to ask about game performance.
Deep Learning GPU Benchmarks 2022
Overview of the benchmarked GPUs
Although we only tested a small selection of all the available GPUs, we think we covered all GPUs that are currently best suited for deep learning training and development due to their compute and memory capabilities and their compatibility to current deep learning frameworks, namely Pytorch and Tensorflow.
For reference also the iconic deep learning GPUs: Geforce GTX 1080 Ti, RTX 2080 Ti and Tesla V100 are included to visualize the increase of compute performance over the recent years.
GTX 1080TI
Suitable for: Workstations
Launch Date: 2017.03
Architecture: Pascal
VRAM Memory (GB): 11 (GDDR5X)
Cuda Cores: 3584
Tensor Cores: —
Power Consumption (Watt): 250
Memory Bandwidth (GB/s): 484
Geforce RTX 2080TI
Suitable for: Workstations
Launch Date: 2018.09
Architecture: Turing
VRAM Memory (GB): 11 (DDR6)
Cuda Cores: 5342
Tensor Cores: 544
Power Consumption (Watt): 260
Memory Bandwidth (GB/s): 616
QUADRO RTX 5000
Suitable for: Workstations/Servers
Launch Date: 2018.08
Architecture: Turing
VRAM Memory (GB): 16 (GDDR6)
Cuda Cores: 3072
Tensor Cores: 384
Power Consumption (Watt): 230
Memory Bandwidth (GB/s): 448
Geforce RTX 3090
Suitable for: Workstations/Servers
Launch Date: 2020. 09
09
Architecture: Ampere
VRAM Memory (GB): 24 (GDDR6X)
Cuda Cores: 10496 Tensor Cores: 328
Power Consumption (Watt): 350
Memory Bandwidth (GB/s): 936
RTX A5000
Suitable for: Workstations/Servers
Launch Date: 2021.04
Architecture: Ampere
VRAM Memory (GB): 24 (GDDR6)
Cuda Cores: 8192
Tensor Cores: 256
Power Consumption (Watt): 230
Memory Bandwidth (GB/s): 768
RTX A5500
Suitable for: Workstations/Servers
Launch Date: 2022.03
Architecture: Ampere
VRAM Memory (GB): 24 (GDDR6)
Cuda Cores: 10240
Tensor Cores: 220
Power Consumption (Watt): 230
Memory Bandwidth (GB/s): 768
RTX A6000
Suitable for: Workstations/Servers
Launch Date: 2020. 10
10
Architecture: Ampere
VRAM Memory (GB): 48 (GDDR6)
Cuda Cores: 10752
Tensor Cores: 336
Power Consumption (Watt): 300
Memory Bandwidth (GB/s): 768
Geforce RTX 4090
Suitable for: Workstations
Launch Date: 2022.10
Architecture: Ada Lovelace
VRAM Memory (GB): 24 (GDDR6X)
Cuda Cores: 16384
Tensor Cores: 512
Power Consumption (Watt): 450
Memory Bandwidth (GB/s): 1008
RTX 6000 Ada
Suitable for: Workstations/Servers
Launch Date: 2022.09
Architecture: Ada Lovelace
VRAM Memory (GB): 48 (GDDR6)
Cuda Cores: 18176
Tensor Cores: 568
Power Consumption (Watt): 300
Memory Bandwidth (GB/s): 960
Tesla V100
Suitable for: Servers
Launch Date: 2017. 05
05
Architecture: Volta
VRAM Memory (GB): 16 (HBM2)
Cuda Cores: 5120
Tensor Cores: 640
Power Consumption (Watt): 250
Memory Bandwidth (GB/s): 900
A100
Suitable for: Servers
Launch Date: 2020.05
Architecture: Ampere
VRAM Memory (GB): 40/80 (HBM2)
Cuda Cores: 6912
Tensor Cores: 512
Power Consumption (Watt): 300
Memory Bandwidth (GB/s): 1935 (80 GB PCIe)
h200
Suitable for: Servers
Launch Date: 2022.10
Architecture: Grace Hopper
VRAM Memory (GB): 80 (HBM2)
Cuda Cores: 14592
Tensor Cores: 456
Power Consumption (Watt): 350
Memory Bandwidth (GB/s): 2000
The Deep Learning Benchmark
The visual recognition ResNet50 model (version 1. 5) is used for our benchmark. As the classic deep learning network with its complex 50 layer architecture with different convolutional and residual layers, it is still a good network for comparing achievable deep learning performance. As it is used in many benchmarks, a close to optimal implementation is available, driving the GPU to maximum performance and showing where the performance limits of the devices are.
5) is used for our benchmark. As the classic deep learning network with its complex 50 layer architecture with different convolutional and residual layers, it is still a good network for comparing achievable deep learning performance. As it is used in many benchmarks, a close to optimal implementation is available, driving the GPU to maximum performance and showing where the performance limits of the devices are.
The comparison of the GPUs have been made using synthetic random image data, to avoid the influence of external elements like the type of dataset storage (SSD or HDD), data loader and data format.
Regarding the setup used, we have to remark two important points. The first one is the XLA feature. A Tensorflow performance feature that was declared stable a while ago, but is still turned off by default. XLA (Accelerated Linear Algebra) does optimize the network graph by dynamically compiling parts of the network to kernels optimized for the specific device. This can have performance benefits of 10% to 30% compared to the static crafted Tensorflow kernels for different layer types. This feature can be turned on by a simple option or environment flag and maximizes the execution performance.
This can have performance benefits of 10% to 30% compared to the static crafted Tensorflow kernels for different layer types. This feature can be turned on by a simple option or environment flag and maximizes the execution performance.
The second one is the employment of mixed precision. Concerning inference jobs, a lower floating point precision is the standard way to improve performance. For most training situation float 16bit precision can also be applied for training tasks with neglectable loss in training accuracy and can speed-up training jobs dramatically. Applying float 16bit precision is not that trivial as the model layers have to be adjusted to use it. As not all calculation steps should be done with a lower bit precision, the mixing of different bit resolutions for calculation is referred as mixed precision.
The Python scripts used for the benchmark are available on Github here.
The Testing Environment
As AIME offers server and workstation solutions for deep learning tasks, we used our AIME A4000 server and our AIME T600 Workstation for the benchmark.
The AIME A4000 server and AIME T600 workstation are elaborated environments to run high performance multiple GPUs by providing sophisticated power and cooling, necessary to achieve and hold maximum performance and the ability to run each GPU in a PCIe 4.0 x16 slot directly connected to the CPU.
The technical specs to reproduce our benchmarks are:
For server compatible GPUs: AIME A4000, AMD EPYC 7543 (32 cores), 128 GB ECC RAM
For GPUs only available for workstations: T600, AMD Threadripper Pro 5955WX (16 cores), 128 GB ECC RAM
Using the AIME Machine Learning Container (MLC) management framework with the following setup:
- Ubuntu 20.04
- NVIDIA driver version 520.61.5
- CUDA 11.2
- CUDNN 8.2.0
- Tensorflow 2.9.0 (official build)
As the NVIDIA h200 and the RTX 4090 are not supported by the official Tensorflow build, below configuration was used for the NVIDIA h200 and the RTX 4090 GPU:
- CUDA 11.8
- CUDNN 8.
 6.0
6.0 - Tensorflow 2.9.1 (NVIDIA build)
The results of our measurements is the average of images per second that could be trained while running for 50 steps at the specified batch size. The average of three runs were taken, the start temperature of all GPUs was below 50° Celsius.
The GPU speed-up compared to a 32-core-CPU rises here several orders of magnitude, making GPU computing not only feasible but mandatory for high performance deep learning tasks.
Next the results using mixed precision.
One can see that using mixed precision option can increase the performance up to three times.
Multi GPU Deep Learning Training Performance
The next level of deep learning performance is to distribute the work and training loads across multiple GPUs. The AIME A4000 and the AIME T600 support up to four server capable GPUs.
Deep learning does scale well across multiple GPUs. The method of choice for multi GPU scaling is to spread the batch across the GPUs. Therefore the effective (global) batch size is the sum of the local batch sizes of each GPU in use. Each GPU does calculate the backpropagation for the applied inputs of the batch slice. The backpropagation results of each GPU are then summed and averaged. The weights of the model are adjusted accordingly and have to be distributed back to all GPUs.
Therefore the effective (global) batch size is the sum of the local batch sizes of each GPU in use. Each GPU does calculate the backpropagation for the applied inputs of the batch slice. The backpropagation results of each GPU are then summed and averaged. The weights of the model are adjusted accordingly and have to be distributed back to all GPUs.
Concerning the data exchange, there is a peak of communication happening to collect the results of a batch and adjust the weights before the next batch can be calculated. While the GPUs are working on calculation a batch not much or no communication at all is happening across the GPUs.
In this standard solution for multi GPU scaling one has to make sure that all GPUs run at the same speed, otherwise the slowest GPU will be the bottleneck for which all GPUs have to wait for! Therefore mixing of different GPU types is not useful.
The next two graphs show how well the RTX 3090 scales by using single and mixed precision.
A good linear and constant scale factor of around 0. 9 is reached, meaning that each additional GPU add around 90% of its theoretical linear performance. The similar scale factor is obtained employing mixed precision.
9 is reached, meaning that each additional GPU add around 90% of its theoretical linear performance. The similar scale factor is obtained employing mixed precision.
Conclusions
Mixed Precision can speed-up the training by more than factor 2
A feature definitely worth a look in regards of performance is to switch training from float 32 precision to mixed precision training. Getting a performance boost by adjusting software depending on your constraints could probably be a very efficient move to double the performance.
Multi GPU scaling is more than feasible
Deep Learning performance scales well with multi GPUs for at least up to 4 GPUs: 2 GPUs can often outperform the next more powerful GPU in regards of price and performance.
Mixing of different GPU types is not useful
Best GPU for Deep Learning?
As in most cases there is not a simple answer to the question. Performance is for sure the most important aspect of a GPU used for deep learning tasks but not the only one.
Performance is for sure the most important aspect of a GPU used for deep learning tasks but not the only one.
So it highly depends on what your requirements are. Here are our assessments for the most promising deep learning GPUs:
RTX 3090
The RTX 3090 is still the flagship GPU of the RTX Ampere generation. It has an unbeaten price/performance ratio that still holds at the end of the year 2022. Only performance improvements or a price adjustment of the latest GPU generation will change this.
RTX A5000
The little brother of the RTX 3090. Now available in a similair price range as the RTX 3090 and with an impressive Performance / Watt ratio the RTX A5000 has become a very interessting alternative to the RTX 3090.
RTX A6000
The bigger brother of the RTX 3090. With its 48 GB GDDR6 memory it is a more future proof version of the RTX 3090 which will also be able to load increasingly larger models.
NVIDIA A100 (40 GB and 80GB)
In case the most performance regardless of price and highest performance density is needed, the NVIDIA A100 is first choice: it delivers high end deep learning performance.
The lower power consumption of 250/300 Watt compared to the 700 Watt of a dual RTX 3090 setup with comparable performance reaches a range where under sustained full load the difference in energy and cooling costs might become a factor to consider.
Moreover, concerning solutions with the need of virtualization to run under a Hypervisor, for example for cloud renting services, it is currently the best choice for high-end deep learning training tasks.
A octa NVIDIA A100 setup, like possible with the AIME A8000, catapults one into multi petaFLOPS HPC computing area.
RTX 4090
The first available NVIDIA GPU of the Ada Lovelace generation. The first results are promising but compatibility to current Deep Learning frameworks is a work in progress. Especially the multi-GPU support is not working yet reliable (December 2022). So currently the RTX 4090 GPU is only recommendable as a single GPU system.
NVIDIA h200
The NVIDIA h200 just became available in late 2022 and therefore the integration in Deep Learning frameworks (Tensorflow / Pytorch) is still lacking. As NVIDIA promised larger performance improvements with CUDA version 12 the full potential of the h200 has still to be discovered. We are curious.
As NVIDIA promised larger performance improvements with CUDA version 12 the full potential of the h200 has still to be discovered. We are curious.
This article will be updated with new additions and corrections as soon as available.
Questions or remarks? Please contact us under: [email protected]
|
3DNews Technologies and IT market. Video card news Users of the reference Radeon RX 7900 XT…
12/22/2022 [16:50], Nikolai Khizhnyak Many reviewers praised the reference design of the new Radeon RX 7900 XTX and RX 7900 XT graphics cards, citing only two 8-pin power connectors and a fairly compact size for ease of use. At the same time, according to HardwareLuxx, complaints from some owners of reference versions of these accelerators about overheating and high noise levels of the cooling system began to appear on the Web.
Image source: AMD over 20 degrees Celsius. In other words, if the average temperature of the GPU reaches 80 degrees Celsius, then the temperature at the hottest point of the chip will not exceed 100 degrees. Overheating in this case does not occur and the GPU will not reset the operating frequency. Image source: AMD
At the same time, some owners of the reference versions of video cards complained about a much larger difference between the average and maximum temperature of the GPU. In some cases, it was as much as 53 degrees Celsius (56 degrees for the GPU on average and 109 degrees for its hotspot). This means that the chip at a quite acceptable average temperature of about 60 degrees Celsius can start to reset the frequency (throttling) for cooling, since at the hottest point the temperature indicator will reach the maximum allowable value of 110 degrees. The difference between the average GPU temperature (orange) and its hotspot temperature (red) . An AMD spokesperson confirmed to HardwareLuxx that they are aware of these complaints: «Our GPU team is currently investigating this issue» . The absence of such complaints about the non-reference versions of the Radeon RX 7900 XTX and RX 7900 XT hints that the reference AMD cooling system of these video cards may be the source of the problem. HardwareLuxx does not jump to conclusions, but suggests that the task of cooling the Navi 31 GPU, which is used at the heart of these video cards, may be complicated by the fact that this GPU uses a chiplet design. In particular, journalists noted that «The reason for the high temperature difference may be uneven pressure between the contact pad of the cooling system and the GPU» . In turn, other reviewers note that the central GCD chiplet with graphics cores and six auxiliary MCD crystals with cache memory of the Navi 31 processor are on the same level. Thus, the reason for the uneven contact of the chip with the cooling system may be something else. AMD Navi 31 GPU. Image Source: TechPowerUp Tom’s Hardware reports that when testing the reference versions of the Radeon RX 7900 XTX and RX 7900 XT, they did not notice a significant difference between the average and maximum GPU temperatures, did not observe throttling or clearly excessive noise cooling systems. The maximum GPU temperature remained within a reasonable 70 degrees Celsius. However, journalists complained that under the most intense loads, for example, in the FurMark stress test, the graphics chip worked at very low frequencies of 1650-1700 MHz, not overclocking to higher frequencies, despite the temperature headroom. The same situation in FurMark was observed in other reviewers of these video cards. Sources:
If you notice an error, select it with the mouse and press CTRL+ENTER. Related materials Permanent URL: Tags: ← В |
 Image Source: HardwareLuxx
Image Source: HardwareLuxx  For example, the GPU bezel that surrounds the GPU dies.
For example, the GPU bezel that surrounds the GPU dies. Why Founders Edition GPUs are good — is it worth buying
Are Founders Edition GPUs good? If so, should they be chosen over other GPU options?
Today I’m going to tell you everything you need to know about the Founders Edition graphics cards, and by the time I’m done, you’ll know for sure if you should choose one of them.
What is the Founders Edition 9 GPU0085
Before I explain in detail what the Founders Edition graphics card is, it’s important to understand how graphics cards are distributed.
While all current PC graphics cards are made by Nvidia or AMD (Intel joining soon), you will most likely be buying a graphics card from one of their hardware partners, not from AMD or Nvidia themselves.
For graphics cards other than Founders Edition, the process is something like this:
- Nvidia makes the GPU. Not a full-fledged video card, but a necessary GPU chip for the video card to work.
- After the GPU is manufactured, it is sent to AIB partner (Add-In Board) . These are well-known GPU brands such as EVGA and Gigabyte.
- Once the respective AIB partner has the chip, they can do whatever they want with it before releasing the graphics card (within limits).
 It means adding its own cooling to it, assembling chips for more high-performance overclocked versions of the video card, and so on .
It means adding its own cooling to it, assembling chips for more high-performance overclocked versions of the video card, and so on .
With the Founders Edition graphics card, the process is as follows:
- Nvidia manufactures GPUs and «selects» some of the high quality chips. The ones they don’t keep go to the AIB partners in the process described above.
- Once Nvidia has perfect chips, they will be able to embed them in their own Founders Edition cards with custom cooling. Also, these Founders Edition cards will often run at higher clock speeds than the «reference» spec that is sent to AIB partners, but AIB partners tend to overclock and tune their graphics cards anyway.
- Since there is no middleman anymore, Nvidia is free to sell its Founders Edition graphics cards and make more profit than if they were sold by partner AIB.
Therefore, a Founders Edition graphics card is a graphics card that you buy directly from Nvidia, not from a partner. It’s like buying a reference or «standard» GPU, and they’re supposed to be cheaper. In fact, ever since Nvidia launched the Founders Edition line in 2016, FE graphics cards have been seen as premium products at a premium from the base GPU.
Does AMD have Founders Edition 9 GPUs?0085
No.
While AMD has reference design graphics cards that it sells directly to consumers, they have no marketing or price premium over non-reference graphics cards.
This is exactly what Nvidia did before the release of the GTX 10 series in 2016, but since then only AMD has carried the torch of selling cheap reference design graphics cards directly to consumers.
This in no way makes buying reference GPUs from AMD a worse option, especially if you’re looking for a graphics card that outsells Nvidia’s equivalent in price.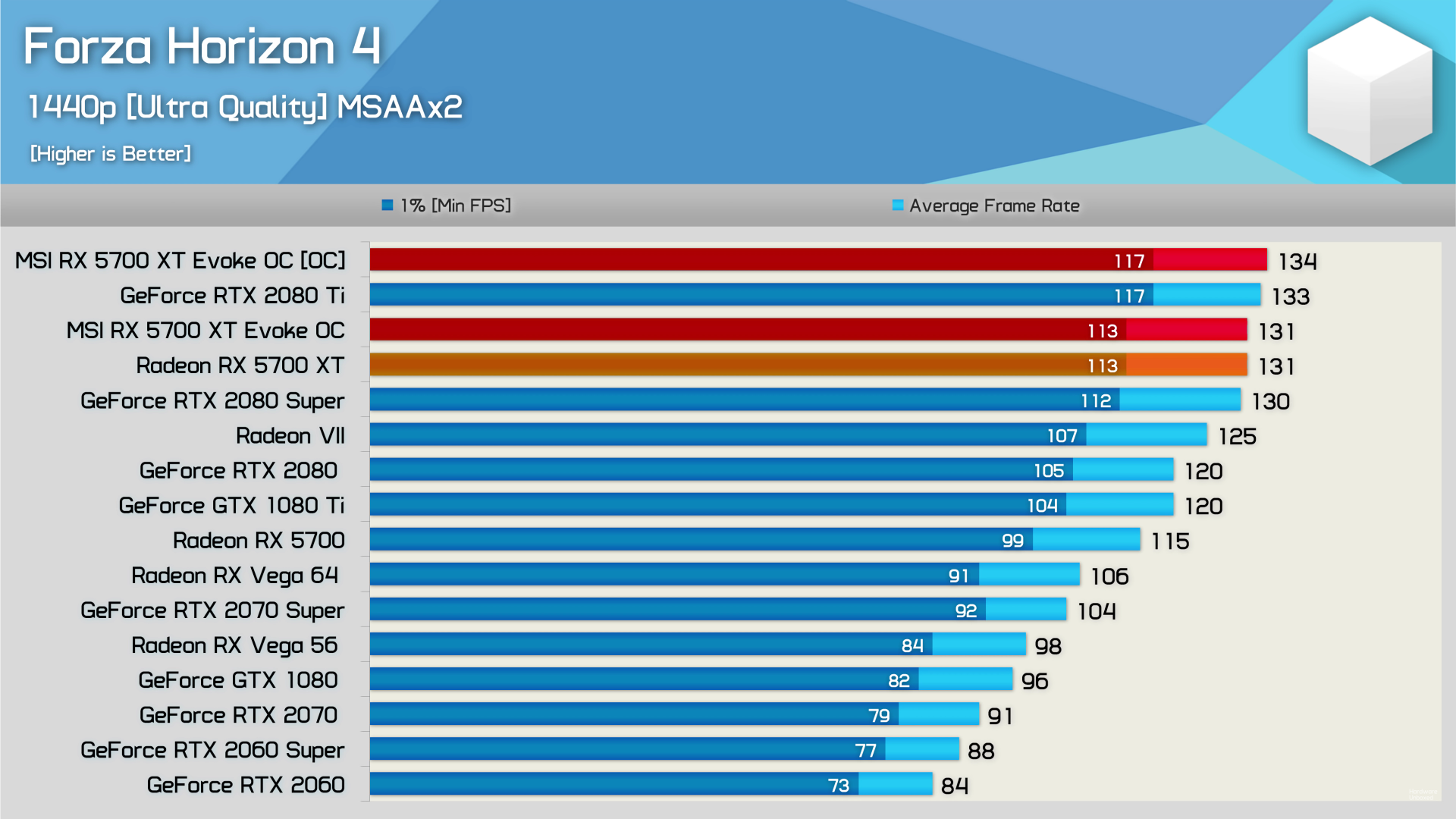
Are Founders Edition cards always fan cooled
A common myth these days is that all Founders Edition cards are blower style, but is a myth which is based on some facts.
Although this is not the case now, there was a time when the standard designs of Nvidia and AMD only released blown cooled, and not open or any alternatives.
Starting with the release of the RTX 20 series, Nvidia began using a dual-fan open cooling design for its Founders Edition graphics cards instead of the traditional fan cooler design.
The RTX 30 series still uses dual fans, but it’s kind of a hybrid between the two design styles, as one fan blows air out of the case and the other pushes air up through the heatsink (and pushes some heat into the case) .
For a well ventilated case other than the Mini ITX, it is generally preferable to use an open graphics card.
open-cooled graphics cards tend to run a little quieter, cooler, and faster than their blower-style counterparts, especially when factory overclocked, which is common with both Nvidia and other GPU vendors.
However, there are scenarios where a blower-style graphics card is better than an open alternative.
If you’re building a Mini ITX case or hoping to run a multi-GPU setup (both scenarios where the exposed graphics card will choke and dissipate more heat to the rest of the PC), a blown cooling system will work much better.
This is because two different styles of video card cooling dissipate heat differently .
An open-cooled graphics card gets rid of heat by dissipating it in almost all directions after taking in cool air from the fans. This is fine with the in a large case with the good airflow of the , but becomes problematic if the cooling fans don’t have enough room to breathe.
Also, if the airflow is poor, you run the risk of your graphics card making other components in your system hotter, as this heat is not dissipated effectively from your machine.
Meanwhile, the blown graphics card takes all the air from one fan. .. and exhausts it outside the case.
.. and exhausts it outside the case.
Whether you install graphics cards in a multi-GPU configuration (or NVLink configuration if you’re thinking Nvidia) or embed in a Mini ITX case, you can get better results with a blower-style graphics card.
Speaking of Founders Edition graphics cards specifically, the RTX 30 FE series is well balanced for both scenarios.
Why Founders Edition is better than other graphics cards
If Nvidia is willing to increase the price and advertise the Founders Edition graphics card, what makes them so much better than other options?
Founders Edition graphics cards have replaced cheaper reference design cards in the market and indicate Nvidia’s willingness to compete directly with its partners.
I think it’s fair to say that Nvidia should be ready to support:
Binning
To answer this question, let’s discuss binning . We briefly mentioned this process earlier in the article, but now it’s time to explain it in a little more detail.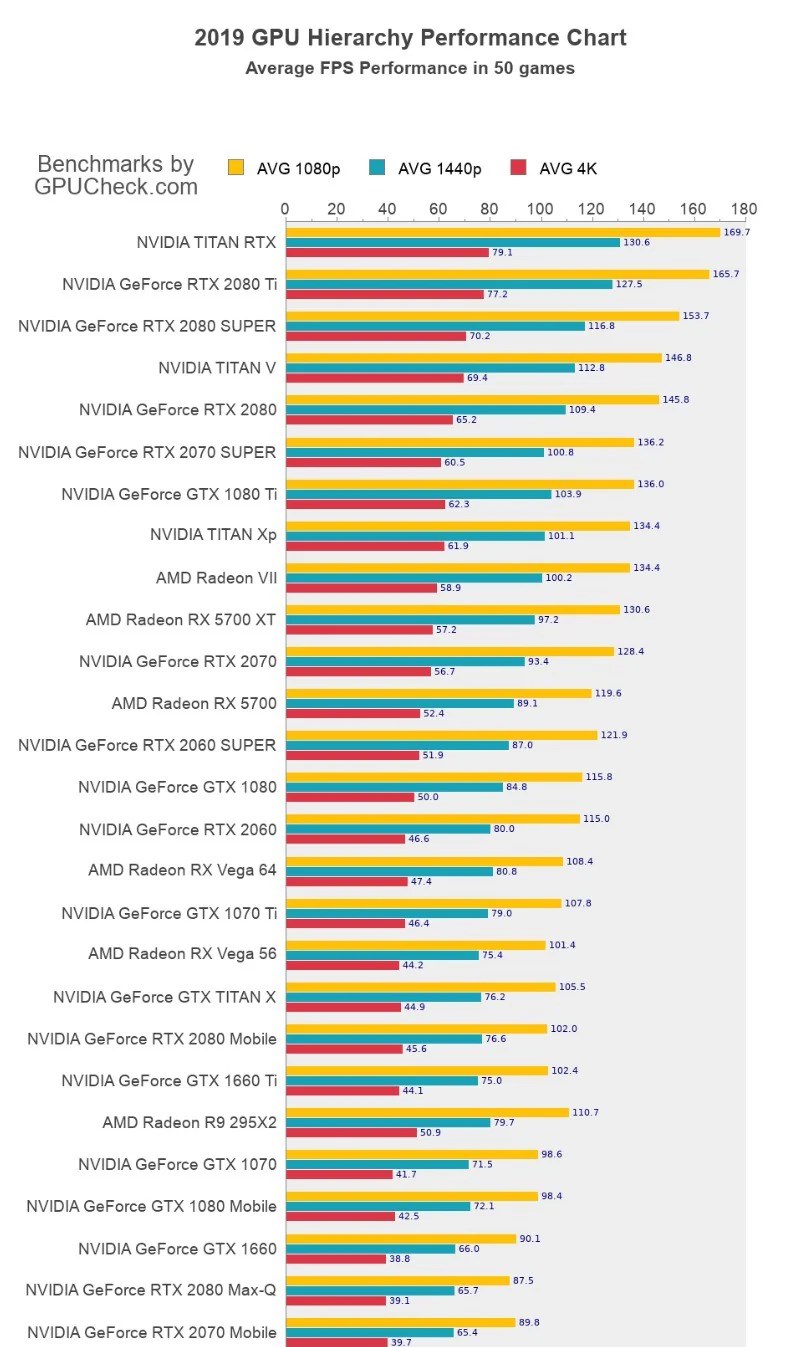
Essentially, in the production of any processor (GPU or CPU), something called the binning process takes place.
The binning process involves testing each chip produced and «grouping» them based on performance.
An interesting thing about binning is that it can sometimes lead to a completely new product. For example, suppose Intel is trying to build a six-core Intel processor, but learns through the binning process that two of those cores aren’t performing well enough to sell the whole package.
It would be a waste of good stuff to just throw it all away, so instead the CPU is renamed to quad-core, dead cores are disabled, and the final product is sold to consumers.
In the case of Founders Edition cards, binning is one of the reasons they are considered a good option.
Since Nvidia is in charge of manufacturing all of its GPU chips, it can select high performance chips for use with Founders Edition graphics cards before selling the rest to its partners.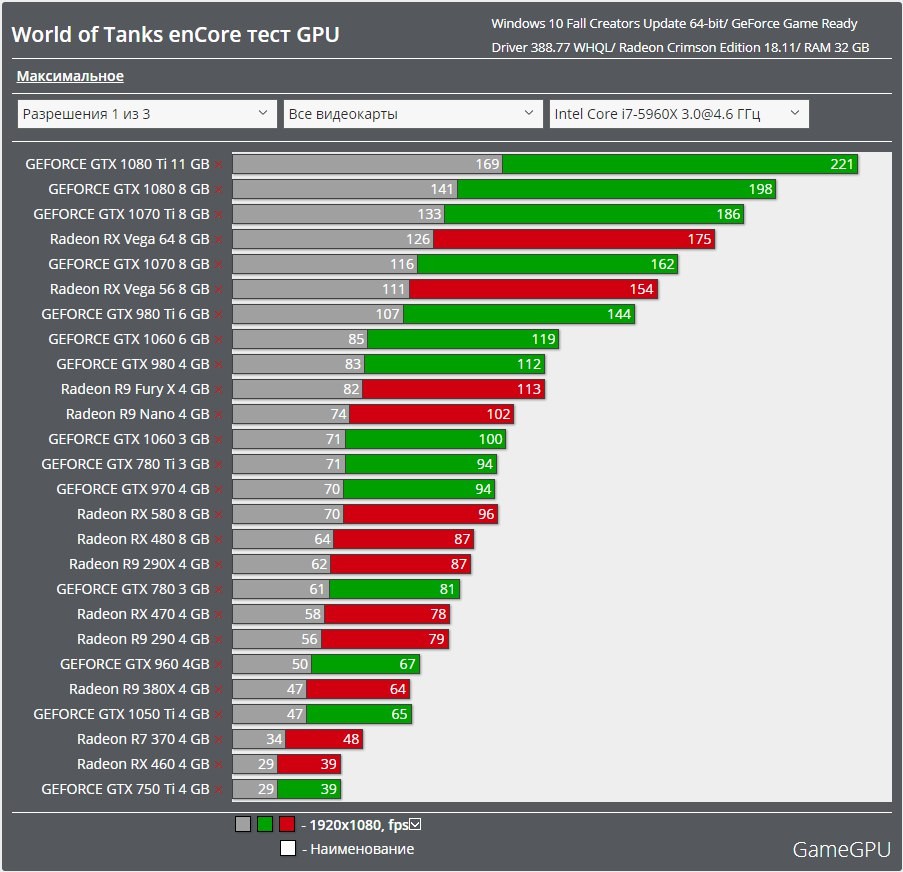
However, this does not mean that every partner video card has a weak chip — many high-end video cards are also carefully selected.
In addition to binning, it is also worth discussing prices and cooling .
If you are lucky enough to receive the Founders Edition video card when it is available for direct sale on the Nvidia website, you will receive the card at the manufacturer’s suggested retail price instead of the wildly inflated prices elsewhere .
Unfortunately, this is practically not realistic, and outside of this scenario, Founders Edition cards can be more expensive than than alternatives.
Meanwhile, the current generation Founders Edition graphics cards cool quite well thanks to their hybrid approach to cooler design.
With good binning in addition to good cooling, Founders Edition graphics cards are a viable overclocking choice that will help enthusiasts squeeze some extra performance and life out of a graphics card.
What are the disadvantages of Founders Edition cards?
Now let’s discuss what are the disadvantages of Founders Edition video cards.
The big issue is the price, especially if you don’t buy directly from Nvidia. Even before the chip shortage, Founders Edition cards shipped at a price premium over budget options from AIB partners.
During the pandemic, when most video cards were sold in stores or from speculators at prices is much higher than the MSRP, this difference has become less obvious… but it’s not what I would call a victory for the Founders Edition cards.
The next is still raw performance and overclocking potential .
While it’s true that the Founders Edition cards are pretty good in this regard, they don’t quite match the highest-end graphics cards from Nvidia’s partners. For example, I’d go with the high-end EVGA RTX 3060 over the Founders Edition RTX 3060 any day of the week, and not just for better cooling or slightly higher overclocking.
Founders Edition graphics cards can clearly outperform budget partner cards, but when partners choose to compete with their own binning and cooling… Nvidia doesn’t always come out on top. Such is the nature of the competition of «hardware partners».
Founders Edition Video Card Frequently Asked Questions
Are the reference cards equivalent to Founders Edition?
No . Although some partners still produce reference Nvidia graphics cards, the Founders Edition cards differ significantly from the reference cards that Nvidia used to sell.
We discussed why in detail in the article above, but in short, the Founders Edition graphics card is designed to directly compete with custom designs from partners, and not to provide a cheaper entry point.
What alternatives are there for Founders Edition graphics cards?
If you’re not sure whether to get a Founders Edition card, or just want an idea of what else to consider, you’ve come to the right place.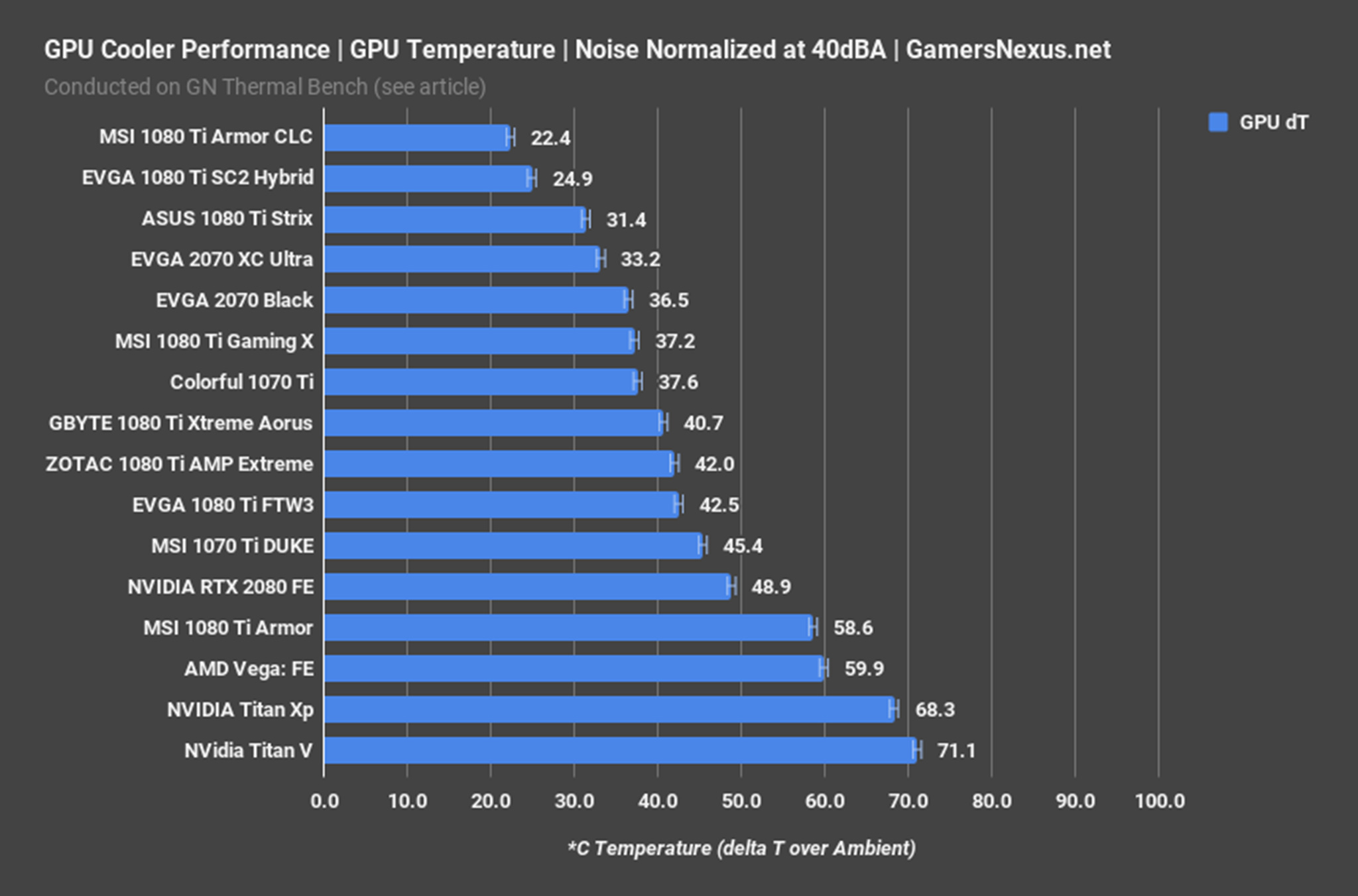
First, let’s talk about a few options that become available when you get an Nvidia graphics card from a partner instead of Nvidia.
These options include:
- Smaller versions of the GPU in question. Not all GPUs have more compact partner versions, but for those that do, getting a smaller graphics card that can actually fit into a compact case may be a better option than the bulkier design of a Founders Edition or partner graphics card.
- High-end video cards with better cooling, better overclocking potential, or both . Especially from brands like EVGA, there are plenty of options for great Nvidia graphics cards without having to buy the Founders Edition. You’re unlikely to be liquid-cooled with the Founders Edition, but the EVGA card may come with liquid cooling!
- Complete graphics cards for use in multi-GPU configurations or Mini ITX PC builds. As discussed earlier in the article, fan cooling has its own unique benefits, and the current generation of Founders Edition cards still push some of the heat to the rest of the case.