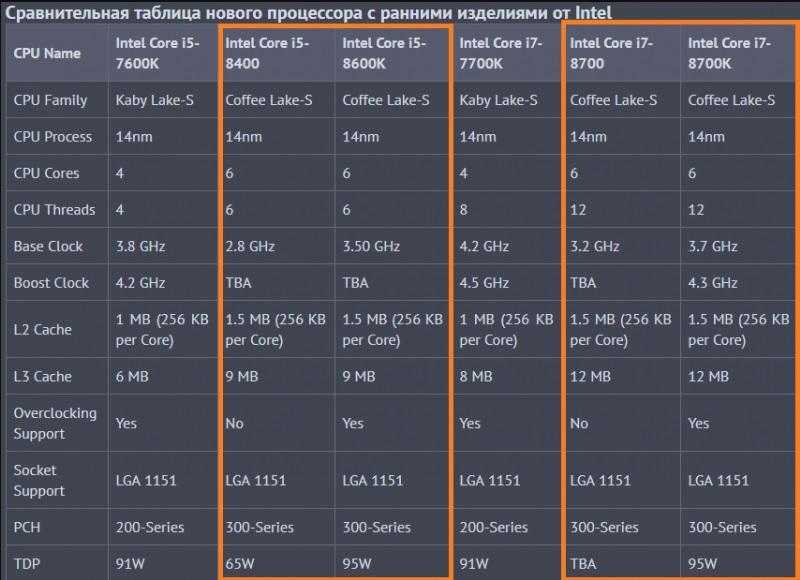
What Is a CPU Core? A Basic Definition
Skip to main content
When you purchase through links on our site, we may earn an affiliate commission. Here’s how it works.
A CPU core is a CPU’s processor. In the old days, every processor had just one core that could focus on one task at a time. Today, CPUs have been two and 18 cores, each of which can work on a different task. As you can see in our CPU Benchmarks Hierarchy, that can have a huge impact on performance.
A core can work on one task, while another core works a different task, so the more cores a CPU has, the more efficient it is . Many processors, especially those in laptops, have two cores, but some laptop CPUs (known as mobile CPUs), such as Intel’s 8th Generation processors, have four. You should shoot for at least four cores in your machine if you can afford it.
Most processors can use a process called simultaneous multithreading or, if it’s an Intel processor, Hyper-threading (the two terms mean the same thing) to split a core into virtual cores, which are called threads . For example, AMD CPUs with four cores use simultaneous multithreading to provide eight threads, and most Intel CPUs with two cores use Hyper-threading to provide four threads.
Some apps take better advantage of multiple threads than others. Lightly-threaded apps, like games, don’t benefit from a lot of cores, while most video editing and animation programs can run much faster with extra threads.
Note: Intel also uses the term “Core” to brand some of its CPUs (ex: Intel Core i7-7500U processor). Of course, Intel CPUs (and all CPUs) that do not have the Core branding use cores as well. And the numbers you see in an Intel Core (or otherwise) processor is not a direct correlation to how many cores the CPU has. For example, the Intel Core i7-7500U processor does not have seven cores.
This article is part of the Tom’s Hardware Glossary .
Further reading:
- How to check CPU temperature
- Do You Really Need 32 Cores?
- How to Buy the Right CPU
- Best Gaming CPUs
- Best Workstation CPUs
- CPU Benchmarks Hierarchy
- CPUs: Reviews
Get instant access to breaking news, in-depth reviews and helpful tips.
Contact me with news and offers from other Future brandsReceive email from us on behalf of our trusted partners or sponsors
Scharon Harding has a special affinity for gaming peripherals (especially monitors), laptops and virtual reality. Previously, she covered business technology, including hardware, software, cyber security, cloud and other IT happenings, at Channelnomics, with bylines at CRN UK.
Topics
Components
CPUs
Tom’s Hardware is part of Future US Inc, an international media group and leading digital publisher. Visit our corporate site .
©
Future US, Inc. Full 7th Floor, 130 West 42nd Street,
New York,
NY 10036.
Processor Cores Definition | Law Insider
-
means a corporation, or a parent or subsidiary thereof within the meaning of Section 424(a) of the Code, which issues or assumes a stock option in a transaction to which Section 424(a) of the Code applies.
-
means the Person (or, if so elected by the Holder, the Parent Entity) formed by, resulting from or surviving any Fundamental Transaction or the Person (or, if so elected by the Holder, the Parent Entity) with which such Fundamental Transaction shall have been entered into.
-
means a firearm as defined in 18 USC §921 for purposes of the Gun-Free Schools Act. It also means any other gun, BB gun, pistol, revolver, shotgun, rifle, machine gun, disguised gun, dagger, dirk, razor, stiletto, switchblade knife, gravity knife, brass knuckles, sling shot, metal knuckle knife, box cutters, cane sword, electronic dart gun, Kung Fu star, electronic stun gun, pepper spray or other noxious spray, explosive or incendiary bomb, or other device, instrument, material or substance that can cause physical injury or death when used to cause physical injury or death.
-
means the personal care and maintenance activities provided to individuals for the purpose of promoting normal standards of health and hygiene.
-
means the APMSIDC, the purchasing agency
-
means the total of all activities performed by the Design-Builder, Designer, Construction Inspection Professional Engineering Firm and the Materials Testing Firm or Laboratory, subcontractors, producers or manufacturers to ensure that the Work performed by the Design-Builder conforms to the Contract requirements.
 For design, Quality Control activities shall include, but not be limited to, procedures for design quality, checking, design review including reviews for constructability, and review and approval of Working Plans. For construction, Quality Control activities shall include, but not be limited to, procedures for materials handling and construction quality, inspection, sampling and testing of materials both on site and at the plant(s), field testing of materials, obtaining and verifying Materials Certifications, record keeping, and equipment monitoring and calibration, production process control, and monitoring of environmental compliance. Quality Control also includes documentation of all QC design and construction efforts. The Scope of Work to be performed as part of the Quality Control task may be changed after the RFQ Phase.
For design, Quality Control activities shall include, but not be limited to, procedures for design quality, checking, design review including reviews for constructability, and review and approval of Working Plans. For construction, Quality Control activities shall include, but not be limited to, procedures for materials handling and construction quality, inspection, sampling and testing of materials both on site and at the plant(s), field testing of materials, obtaining and verifying Materials Certifications, record keeping, and equipment monitoring and calibration, production process control, and monitoring of environmental compliance. Quality Control also includes documentation of all QC design and construction efforts. The Scope of Work to be performed as part of the Quality Control task may be changed after the RFQ Phase. -
means a system for disposing of sewage, industrial, or other wastes and includes sewage systems and treatment works.
-
means an individual employed by a home health agency to provide home health services under the direction of a registered nurse or therapist.

-
means processing a higher-value hazardous secondary material in order to manufacture a product that serves a similar functional purpose as the original commercial-grade material. For the purpose of this definition, a hazardous secondary material is considered higher-value if it was generated from the use of a commercial-grade material in a manufacturing process and can be remanufactured into a similar commercial-grade material.
-
means an instrument or device of any kind that is used or designed to be used to inflict harm including, but not limited to, rifles, handguns, shotguns, antique fire- arms, knives, swords, bows and arrows, BB guns, pellet guns, air rifles, electronic or other stun devices, or fighting imple- ments.
-
means a Train Operator succeeding or intended by the Secretary of State to succeed (and whose identity is notified to the Franchisee by the Secretary of State) the Franchisee in the provision or operation of all or any of the Franchise Services including, where the context so admits, the Franchisee where it is to continue to provide or operate the Franchise Services following termination of the Franchise Agreement;
-
means (a) each of the two [Engine Manufacturer and Model] engines (generic manufacturer and model [Generic Manufacturer and Model]) listed by manufacturer’s serial number and further described in Annex A to the Indenture Supplement originally executed and delivered under the Indenture, whether or not from time to time installed on the Airframe or installed on any other airframe or on any other aircraft, and (b) any Replacement Engine that may from time to time be substituted for an Engine pursuant to Section 7.
 04 or 7.05 of the Indenture; together in each case with any and all related Parts, but excluding items installed or incorporated in or attached to any such engine from time to time that are excluded from the definition of Parts. At such time as a Replacement Engine shall be so substituted and the Engine for which substitution is made shall be released from the Lien of the Indenture, such replaced Engine shall cease to be an Engine under the Indenture.
04 or 7.05 of the Indenture; together in each case with any and all related Parts, but excluding items installed or incorporated in or attached to any such engine from time to time that are excluded from the definition of Parts. At such time as a Replacement Engine shall be so substituted and the Engine for which substitution is made shall be released from the Lien of the Indenture, such replaced Engine shall cease to be an Engine under the Indenture.
Processors, cores and threads. Topology of systems / Habr
In this article I will try to describe the terminology used to describe systems that can execute several programs in parallel, that is, multi-core, multi-processor, multi-threaded. Different types of parallelism in the IA-32 CPU appeared at different times and in a somewhat inconsistent order. It’s easy to get confused in all of this, especially given that operating systems are careful to hide details from less sophisticated application programs.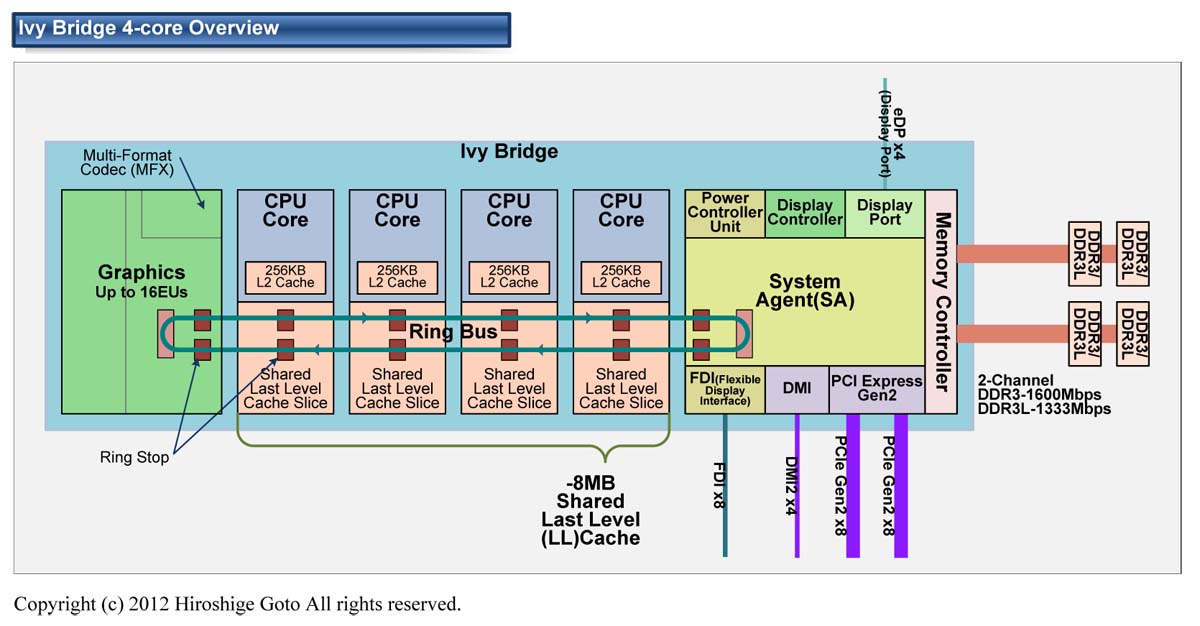
The following terminology is used in the documentation for Intel processors. Other architectures may have other names for similar concepts. Where they are known to me, I will mention them.
The purpose of the article is to show that with all the variety of possible configurations of multiprocessor, multicore and multithreaded systems, the programs running on them are given opportunities both for abstraction (ignoring differences) and for taking into account specifics (the ability to programmatically learn the configuration).
Warning about ®, ™, © in article
My comment explains why company employees should use copyright marks in public communications. In this article, they had to be used quite often.
Processor
Of course, the oldest, most commonly used and ambiguous term is “processor”.
In today’s world, a processor is what we buy in a nice Retail box or not so nice OEM package.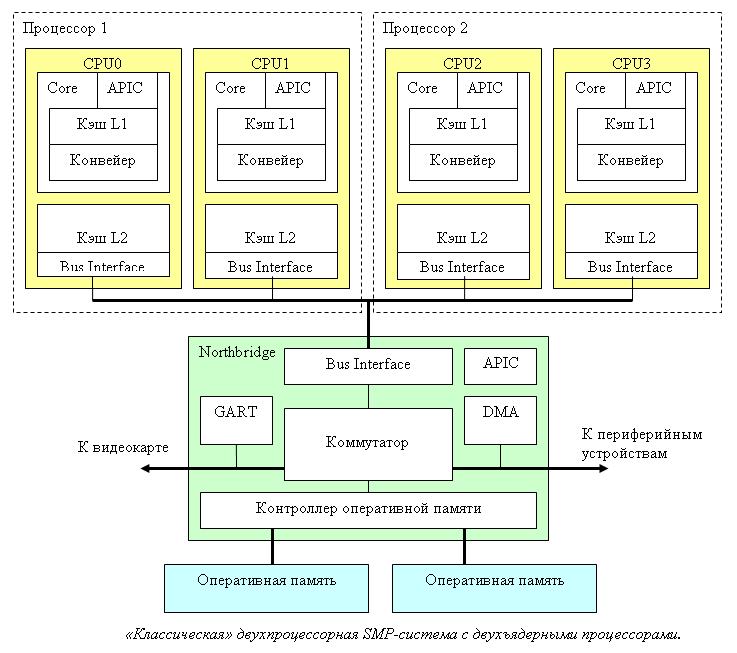 An indivisible entity inserted into a socket on a motherboard. Even if there is no connector and it cannot be removed, that is, if it is tightly soldered, this is one chip.
An indivisible entity inserted into a socket on a motherboard. Even if there is no connector and it cannot be removed, that is, if it is tightly soldered, this is one chip.
Mobile systems (phones, tablets, laptops) and most desktops have a single processor. Workstations and servers sometimes boast two or more processors on the same motherboard.
Support for multiple CPUs in a single system requires numerous system design changes. At a minimum, it is necessary to ensure their physical connection (provide for several sockets on the motherboard), solve the issues of processor identification (see later in this article, as well as my previous note), memory access coordination and interrupt delivery (the interrupt controller must be able to route interrupts on multiple processors) and, of course, support from the operating system. Unfortunately, I could not find a documentary mention of the moment the first multiprocessor system was created on Intel processors, but Wikipedia claims that Sequent Computer Systems shipped them already in 1987, using Intel 80386 processors. Widespread support for multiple chips in a single system becomes available starting with the Intel® Pentium.
Widespread support for multiple chips in a single system becomes available starting with the Intel® Pentium.
If there are several processors, then each of them has its own socket on the board. At the same time, each of them has complete independent copies of all resources, such as registers, executing devices, caches. They share a common memory — RAM. Memory can be connected to them in various and rather non-trivial ways, but this is a separate story that is beyond the scope of this article. The important thing is that in any case, the executable programs must create the illusion of a homogeneous shared memory, accessible from all processors in the system.
Ready to take off! Intel® Desktop Board D5400XS
Core
Historically, multi-core in the Intel IA-32 appeared later than Intel® HyperThreading, but it comes next in the logical hierarchy.
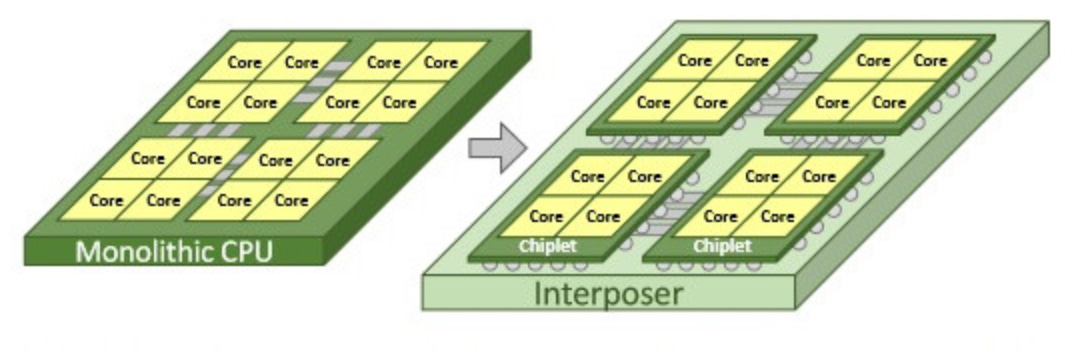
It would seem that if there are more processors in the system, then its performance is higher (on tasks that can use all resources). However, if the cost of communications between them is too high, then all the gain from parallelism is killed by long delays in the transfer of common data. This is exactly what is observed in multiprocessor systems — both physically and logically they are very far from each other. To communicate effectively in such conditions, specialized buses such as the Intel® QuickPath Interconnect have to be invented. Energy consumption, size and price of the final solution, of course, do not decrease from all this. High integration of components should come to the rescue — circuits executing parts of a parallel program must be dragged closer to each other, preferably on one chip. In other words, several cores, identical to each other in everything, but working independently.
However, if the cost of communications between them is too high, then all the gain from parallelism is killed by long delays in the transfer of common data. This is exactly what is observed in multiprocessor systems — both physically and logically they are very far from each other. To communicate effectively in such conditions, specialized buses such as the Intel® QuickPath Interconnect have to be invented. Energy consumption, size and price of the final solution, of course, do not decrease from all this. High integration of components should come to the rescue — circuits executing parts of a parallel program must be dragged closer to each other, preferably on one chip. In other words, several cores, identical to each other in everything, but working independently.
Intel’s first IA-32 multi-core processors were introduced in 2005. Since then, the average number of cores in server, desktop, and now mobile platforms has been steadily growing.
Unlike two single-core processors in the same system that share only memory, two cores can also share caches and other resources responsible for interacting with memory.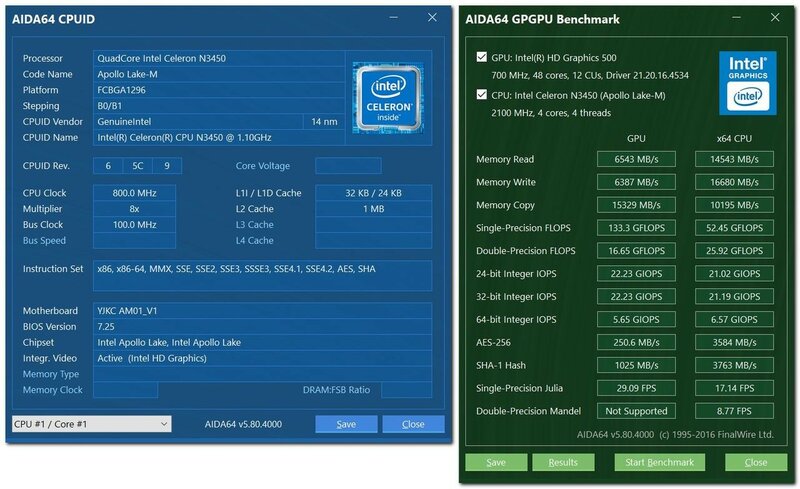 Most often, the caches of the first level remain private (each core has its own), while the second and third levels can be either shared or separate. This organization of the system reduces the delay in data delivery between neighboring cores, especially if they are working on a common task.
Most often, the caches of the first level remain private (each core has its own), while the second and third levels can be either shared or separate. This organization of the system reduces the delay in data delivery between neighboring cores, especially if they are working on a common task.
A micrograph of a quad-core Intel processor codenamed Nehalem. Separate cores, a shared L3 cache, as well as QPI links to other processors and a shared memory controller are highlighted.
Hyperflow
Until about 2002, the only way to get an IA-32 system capable of executing two or more programs in parallel was to use multiprocessor systems specifically. The Intel® Pentium® 4 and the Xeon line codenamed Foster (Netburst) introduced a new technology called hyperthreading or hyperthreading called Intel® HyperThreading (HT).
Nothing new under the sun. HT is a special case of what is referred to in the literature as simultaneous multithreading (SMT). Unlike «real» cores, which are complete and independent copies, in the case of HT, only a part of the internal nodes are duplicated in one processor, primarily responsible for storing the architectural state — registers. The executive nodes responsible for organizing and processing data remain in the singular, and at any time are used by at most one of the threads. Like cores, hyperthreads share caches among themselves, but starting at what level depends on the specific system.
Unlike «real» cores, which are complete and independent copies, in the case of HT, only a part of the internal nodes are duplicated in one processor, primarily responsible for storing the architectural state — registers. The executive nodes responsible for organizing and processing data remain in the singular, and at any time are used by at most one of the threads. Like cores, hyperthreads share caches among themselves, but starting at what level depends on the specific system.
I won’t try to explain all the pros and cons of SMT designs in general and HT designs in particular. The interested reader can find a fairly detailed discussion of the technology in many sources, and of course Wikipedia. However, I will note the following important point, which explains the current restrictions on the number of hyperthreads in real production.
Flow restrictions
In what cases is the presence of «dishonest» multi-core in the form of HT justified? If one application thread is not able to load all the executing nodes inside the kernel, then they can be «borrowed» to another thread.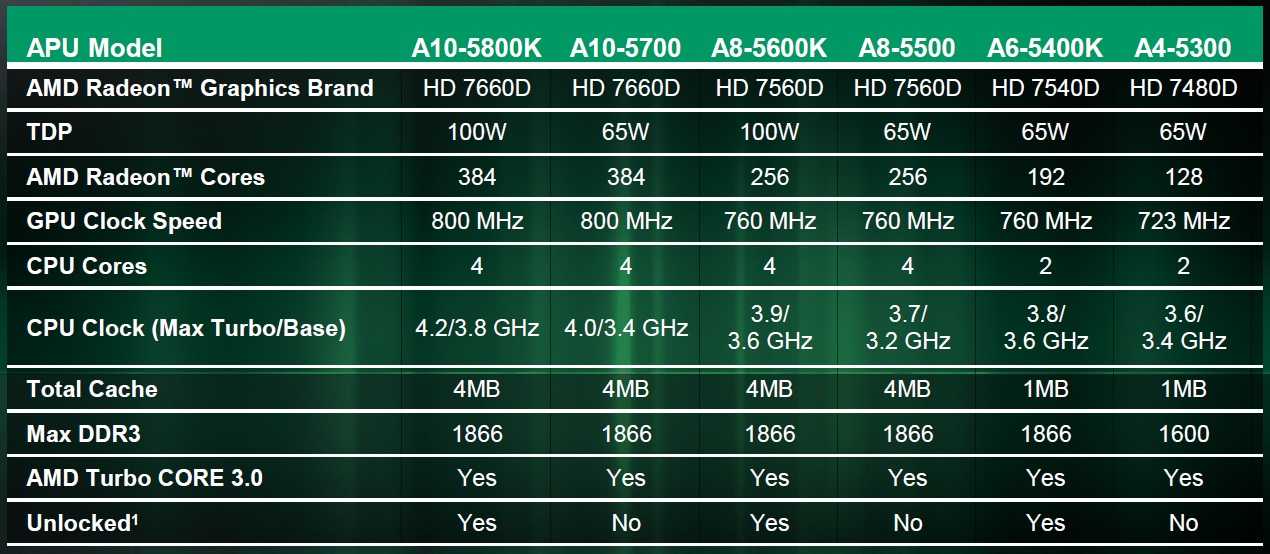 This is typical for applications that have a «bottleneck» not in calculations, but in data access, that is, often generating cache misses and having to wait for data to be delivered from memory. During this time, the kernel without HT will be forced to idle. The presence of HT allows you to quickly switch free executing nodes to another architectural state (because it is just duplicated) and execute its instructions. This is a special case of a technique called latency hiding, when one long operation, during which useful resources are idle, is masked by the parallel execution of other tasks. If the application already has a high degree of utilization of kernel resources, the presence of hyperthreading will not allow for acceleration — “honest” kernels are needed here.
This is typical for applications that have a «bottleneck» not in calculations, but in data access, that is, often generating cache misses and having to wait for data to be delivered from memory. During this time, the kernel without HT will be forced to idle. The presence of HT allows you to quickly switch free executing nodes to another architectural state (because it is just duplicated) and execute its instructions. This is a special case of a technique called latency hiding, when one long operation, during which useful resources are idle, is masked by the parallel execution of other tasks. If the application already has a high degree of utilization of kernel resources, the presence of hyperthreading will not allow for acceleration — “honest” kernels are needed here.
Typical scenarios for desktop and server applications designed for general purpose machine architectures have the potential for parallelism implemented using HT. However, this potential is quickly «used up». Perhaps for this reason, on almost all IA-32 processors, the number of hardware hyperthreads does not exceed two.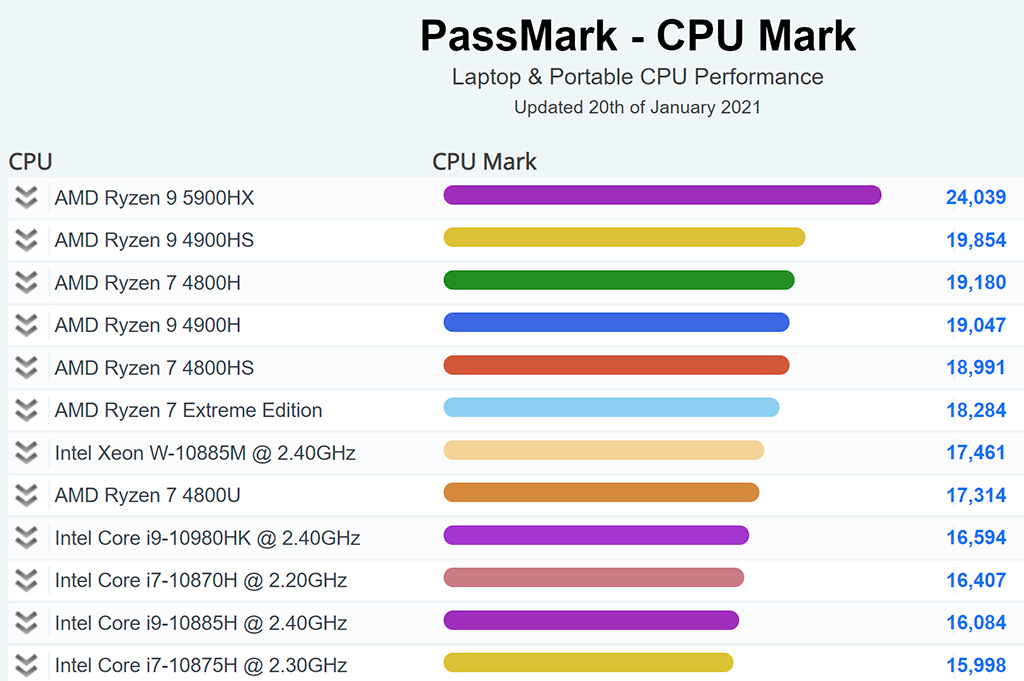 In typical scenarios, the gain from using three or more hyperthreadings would be small, but the loss in die size, power consumption, and cost is significant.
In typical scenarios, the gain from using three or more hyperthreadings would be small, but the loss in die size, power consumption, and cost is significant.
Another situation is observed in typical tasks performed on video accelerators. Therefore, these architectures are characterized by the use of SMT technology with a larger number of threads. Since the Intel® Xeon Phi coprocessors (introduced in 2010) are ideologically and genealogically quite close to graphics cards, they can have four hyperthreads per core, a configuration unique to the IA-32.
Logic processor
Of the three «levels» of parallelism described (processors, cores, hyperthreadings), some or even all of them may be missing in a particular system. This is affected by BIOS settings (multi-core and multi-threading are disabled independently), microarchitecture (for example, HT was absent from the Intel® Core™ Duo, but was brought back with the release of Nehalem), and system events (multiprocessor servers can shut down failed processors in case of malfunctions and continue to «fly» on the remaining ones).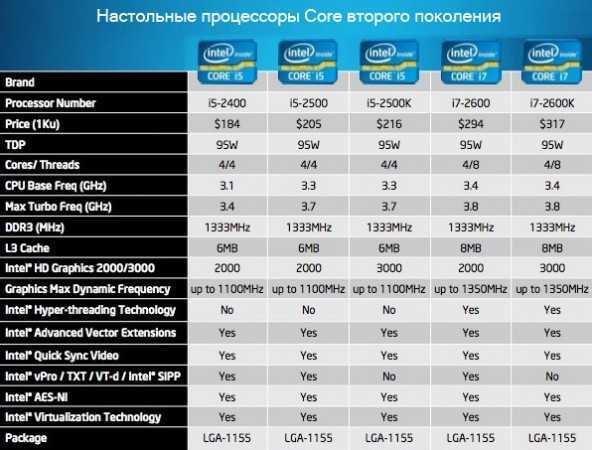 How is this multi-layered zoo of concurrency visible to the operating system and, ultimately, to applications?
How is this multi-layered zoo of concurrency visible to the operating system and, ultimately, to applications?
Further, for convenience, we denote the number of processors, cores, and threads in some system by a triple ( x , y , z ), where x is the number of processors, y is the number of cores in each processor, and z is the number of hyperthreads in each core. Hereafter, I will call this triple topology — a well-established term that has little to do with the section of mathematics. The product p = xyz determines the number of entities called logical processors systems. It defines the total number of independent application process contexts in a shared-memory system executing in parallel that the operating system has to consider. I say «forced» because it cannot control the execution order of two processes that are on different logical processors. This also applies to hyperthreads: although they run «sequentially» on the same core, the specific order is dictated by the hardware and is not visible or controlled by programs.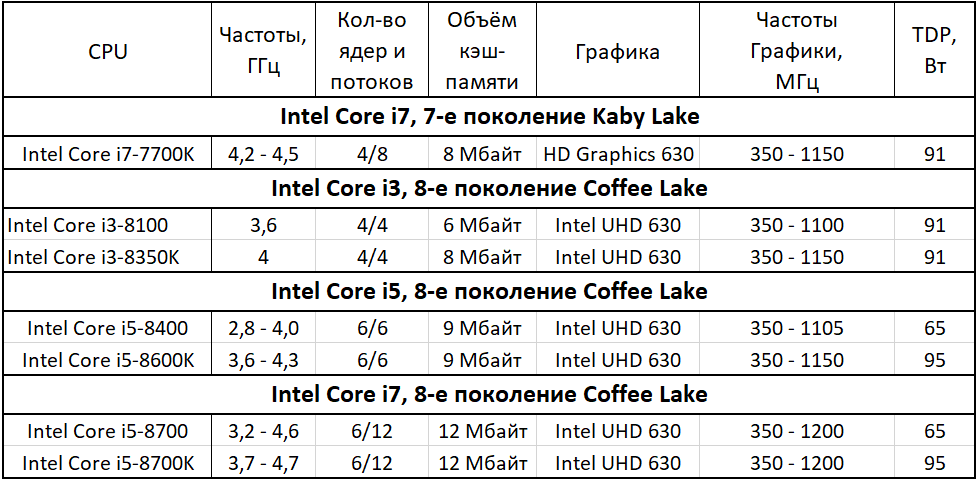
Most often, the operating system hides from the end applications the features of the physical topology of the system on which it is running. For example, the following three topologies: (2, 1, 1), (1, 2, 1) and (1, 1, 2) — the OS will be represented as two logical processors, although the first of them has two processors, the second one has two cores, and the third one is just two threads.
Windows Task Manager shows 8 logical processors; but how much is that in processors, cores and hyperthreads?
Linux top shows 4 logical processors.
This is quite convenient for the creators of application applications — they do not have to deal with hardware features that are often insignificant for them.
Topology software
Of course, abstracting the topology into a single number of logical processors in some cases creates enough grounds for confusion and misunderstanding (in heated Internet disputes). Computing applications that want to get the most performance out of hardware require fine-grained control over where their threads will be placed: closer together on adjacent hyperthreads, or vice versa, further away on different processors. The speed of communication between logical processors within the same core or processor is much faster than the speed of data transfer between processors. The possibility of heterogeneity in the organization of RAM also complicates the picture.
Computing applications that want to get the most performance out of hardware require fine-grained control over where their threads will be placed: closer together on adjacent hyperthreads, or vice versa, further away on different processors. The speed of communication between logical processors within the same core or processor is much faster than the speed of data transfer between processors. The possibility of heterogeneity in the organization of RAM also complicates the picture.
Information about the system topology as a whole, as well as the position of each logical processor in IA-32, is available using the CPUID instruction. Since the advent of the first multiprocessor systems, the logical processor identification scheme has been extended several times. To date, its parts are contained in sheets 1, 4 and 11 of the CPUID. Which of the sheets to look at can be determined from the following block diagram taken from the article [2]:
I will not bore here with all the details of the individual parts of this algorithm. If there is interest, then the next part of this article can be devoted to this. I will refer the interested reader to [2], which deals with this issue in as much detail as possible. Here I will first briefly describe what APIC is and how it relates to topology. Next, consider working with sheet 0xB (eleven in decimal), which is currently the latest word in “apico-building”.
If there is interest, then the next part of this article can be devoted to this. I will refer the interested reader to [2], which deals with this issue in as much detail as possible. Here I will first briefly describe what APIC is and how it relates to topology. Next, consider working with sheet 0xB (eleven in decimal), which is currently the latest word in “apico-building”.
APIC ID
Local APIC (advanced programmable interrupt controller) is a device (now part of the processor) responsible for working with interrupts coming to a specific logical processor. Each logical processor has its own APIC. And each of them in the system must have a unique APIC ID value. This number is used by interrupt controllers for addressing when delivering messages, and by everyone else (such as the operating system) to identify logical processors. The specification for this interrupt controller has evolved from the Intel 8259PIC via Dual PIC, APIC and
xAPIC
to
x2APIC
.
At the moment, the width of the number stored in the APIC ID has reached the full 32 bits, although in the past it was limited to 16, and even earlier to only 8 bits. Today, remnants of the old days are scattered all over the CPUID, but CPUID.0xB.EDX[31:0] returns all 32 bits of the APIC ID. Each logical processor independently executing the CPUID instruction will return a different value.
Clarification of family ties
The APIC ID value by itself says nothing about the topology. To find out which two logical processors are inside the same physical one (i.e., they are “brothers” of hyperthreads), which two are inside the same processor, and which are completely different processors, you need to compare their APIC ID values. Depending on the degree of relationship, some of their bits will match. This information is contained in the sublists CPUID.0xB, which are encoded with an operand in ECX. Each of them describes the position of the bit field of one of the topology levels in EAX[5:0] (more precisely, the number of bits that need to be shifted to the right in the APIC ID to remove the lower topology levels), as well as the type of this level — hyperthread, core or processor , — in ECX[15:8].
Logical processors within the same core will match all APIC ID bits except those belonging to the SMT field. For logical processors that are in the same processor, all bits except for the Core and SMT fields. Since the number of subsheets for CPUID.0xB can grow, this scheme will support the description of topologies with a larger number of levels, if necessary in the future. Moreover, it will be possible to introduce intermediate levels between existing ones.
An important consequence of the organization of this scheme is that in the set of all APIC IDs of all logical processors of the system there can be «holes», i.e. they will not go sequentially. For example, in a multi-core processor with HT disabled, all APIC IDs may turn out to be even, since the least significant bit responsible for encoding the hyperthread number will always be zero.
Note that CPUID.0xB is not the only source of information about logical processors available to the operating system. The list of all processors available to it, along with their APIC ID values, is encoded in the MADT ACPI table [3, 4].
The list of all processors available to it, along with their APIC ID values, is encoded in the MADT ACPI table [3, 4].
Operating systems and topology
Operating systems provide logical processor topology information to applications through their own interfaces.
On Linux, topology information is contained in a pseudo file /proc/cpuinfo , as well as the output of the command dmidecode . In the example below, I’m filtering the contents of cpuinfo on some non-HT quad-core system, leaving only topology entries:
Hidden text
ggg@shadowbox:~$ cat /proc/cpuinfo |grep 'processor\|physical\ id\|siblings\|core\|cores\|apicid' processor: 0 physical id : 0 siblings: 4 core id : 0 cpu cores: 2 apicid : 0 initial apicid : 0 processor : 1 physical id : 0 siblings: 4 core id : 0 cpu cores: 2 apicid : 1 initial apicid : 1 processor: 2 physical id : 0 siblings: 4 core id : 1 cpu cores: 2 apicid : 2 initial apicid : 2 processor: 3 physical id : 0 siblings: 4 core id : 1 cpu cores: 2 apicid : 3 initial apicid : 3
In FreeBSD, the topology is reported via the sysctl mechanism in the kern. sched.topology_spec variable as XML:
sched.topology_spec variable as XML:
Hidden text
user@host:~$ kern.sched.topology_spec:0, 1, 2, 3, 4, 5, 6, 7 0, 1, 2, 3, 4, 5, 6, 7 0, 1 THREAD group SMT group 2, 3 THREAD group SMT group 4, 5 THREAD group SMT group 6, 7 THREAD group SMT group
In MS Windows 8, topology information can be viewed in the Task Manager.
Hidden text
Also provided by the Sysinternals Coreinfo console utility and the GetLogicalProcessorInformation API call.
Complete picture
I will illustrate once again the relationship between the concepts of «processor», «core», «hyperthread» and «logical processor» with several examples.
System (2, 2, 2)
System (2, 4, 1)
System (4, 1, 1)
Other matters
In this section, I took out some curiosities that arise due to the multilevel organization of logical processors.
Caches
As I already mentioned, the caches in the processor also form a hierarchy, and it is quite strongly related to the topology of the cores, but it is not uniquely determined by it. The output of CPUID.4 and its sublists is used to determine which caches are shared for which logical processors and which are not.
Licensing
Some software products come with a number of licenses, determined by the number of processors in the system on which they will be used. Others — the number of cores in the system. Finally, to determine the number of licenses, the number of processors can be multiplied by a fractional «core factor», depending on the type of processor!
Virtualization
Virtualization systems capable of simulating multi-core systems can assign arbitrary topologies to virtual processors within a machine that do not match the actual hardware configuration. So, inside the host system (1, 2, 2), some well-known virtualization systems by default bring all logical processors to the top level, i.e. create configuration (4, 1, 1). Combined with topology-specific licensing features, this can have some funny effects.
Thank you for your attention!
Literature
- Intel Corporation.
 Intel® 64 and IA-32 Architectures Software Developer’s Manual. Volumes 1–3, 2014. www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
Intel® 64 and IA-32 Architectures Software Developer’s Manual. Volumes 1–3, 2014. www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html - Shih Kuo. Intel® 64 Architecture Processor Topology Enumeration, 2012 — software.intel.com/en-us/articles/intel-64-architecture-processor-topology-enumeration
- OSDevWiki. MADT. wiki.osdev.org/MADT
- OSDevWiki. Detecting CPU Topology. wiki.osdev.org/Detecting_CPU_Topology_%2880×86%29
How to enable or disable processor cores in Windows
One of the most exciting new technologies implemented in Intel and AMD processors is turbo mode. It allows you to increase the processor multiplier and thus increase the clock speed. And this will improve performance. A processor with more cores needs more power. This is due to the increase in heat transfer. As a result, the sync rate for systems with many cores is often less than two or single core systems, leading Windows 10 owners to think about enabling all cores.
Windows processor power boost.
How many cores work by default
Overclocking is a good and most obvious way to increase the frequency of AMD and Intel processors. But the processing power of some AMD chips can be increased, and much more will work in a completely new way. AMD is the only manufacturer whose systems are sold with some inactive cores. If you can unlock them, you will get extra power for free. This is especially true for processors with a single core, as well as for some dual-core processors (i.e. three or two cores are active, one or two are inactive). Simple calculations allow us to understand that unlocking the fourth core in a triple-core processor increases its performance by as much as a third — so the game is definitely worth the candle.
The ability to unlock inactive cores interested computer users a few years ago, but back then it required a lot more effort and luck than it does today. First of all, the user had to buy one of the few specific SB750 southbridge boards, and then find a processor in the store that would be able to work after unlocking the core. Unlike tests and experiments, this could not be verified — if someone was lucky, he received one-third of the power for free, but equally all the effort could be wasted.
Unlike tests and experiments, this could not be verified — if someone was lucky, he received one-third of the power for free, but equally all the effort could be wasted.
Some motherboards offer a special switch or button to unlock inactive cores without having to visit the BIOS. Now it’s much easier. Manufacturers have ventured and started using the unlock feature on their motherboards when not all cores work. It is offered by most new boards from ASUS (Core Unlocker), Gigabyte (Auto Unlock), MSI (Unlock CPU Core), and Foxconn (Core Release).
To unlock an inactive kernel, install the processor and then start the computer. After entering the BIOS, find the desired function and activate it. If possible, it’s better to manually activate all cores than rely on automatic settings. After rebooting the computer, all cores should be active. In the case of some boards, the procedure is even simpler — they have buttons that allow you to start inactive kernels without entering the BIOS.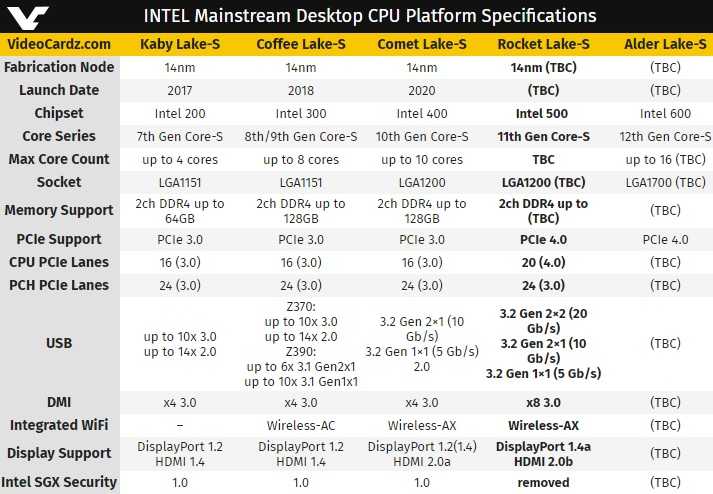
Introduction to the topic
Initially, such a function did not always work well (or did not work at all), but modern manufacturers have long eliminated all problems. There is no negative effect, i.e. an increase in power consumption under load and, consequently, an increase in heat dissipation is a common cooling system for a processor. The only thing that can happen is some reduction in the system’s susceptibility to overclocking. You should not increase the load and power of the system cores.
Modern processors have enormous processing power. Such indicators are achieved not so much by the processor architecture as by the number of cores and their frequency. Single-core systems will not perform more complex tasks. First came dual-core processors, later quad-core processors, and more recently, the number of processor cores reaches 10. They are offered by both AMD and Intel, with the former also selling very popular triple-core processors.
Initially, the creation of three-core systems was a manifestation of AMD’s amazing cunning. Often one of the cores of quad-core processors turned out to be damaged. Since the other three worked well, there were processors on the market with a locked one core that was broken. Because of this, Windows 7 users began to try to run all the processor cores.
Often one of the cores of quad-core processors turned out to be damaged. Since the other three worked well, there were processors on the market with a locked one core that was broken. Because of this, Windows 7 users began to try to run all the processor cores.
Theoretically this is not a problem. However, as in life, theory and practice need not follow the same path. The problem lies in the structure of the software. Many applications simply cannot use multithreading. They have been adapted to run optimally in single and sometimes dual threads, and consequently all «overstock» cores remain unused. Even worse, in such a situation a much cheaper processor, but with faster cores, can perform better than a multi-core speed daemon, having a somewhat limited clock frequency. This is not the end of defects. The cores that are not used consume as much power as is being used at any given time.
Thus, we have a similar situation as in the case of traffic jams. You can even have a Ferrari with a 500 horsepower engine, but you don’t use that power, and the fuel disappears from the tank at an alarming rate, and you drive slower than the Fiat in the next lane.
You can even have a Ferrari with a 500 horsepower engine, but you don’t use that power, and the fuel disappears from the tank at an alarming rate, and you drive slower than the Fiat in the next lane.
Ways to turn on
The solution to all these problems is the turbo mode, associated with a system to turn off or limit the speed of the remaining cores. The clock frequency of the cores of a modern processor is the base value (in the case of Intel processors — 133.3 MHz, AMD — 200 MHz) multiplied by the corresponding number assigned to this model. For example, AMD Phenom II X6 1055T runs at 2800 MHz (200 MHz x 14) and Intel Core i7 870 2933 MHz (133.3 MHz x 22). The number by which we multiply the output value is the multiplier. AMD has long recognized that when you don’t need the full power of the processor, the multiplier can be lowered and therefore power consumption and heat dissipation are reduced. Turbo mode is the reverse procedure — if you need more power, the multiplier and operating frequency increase. However, this is not easy to do.
However, this is not easy to do.
Simply increasing the multiplier will cause the processor’s maximum thermal projection power to be exceeded. Without going into too much detail (AMD and Intel define this parameter quite differently), it can be defined as the amount of heat emitted by the processor, so exceeding it can lead to overheating and damage to the system. The simplest protection that manufacturers use disables turbo mode after exceeding the maximum multiplier value.
To avoid this, a procedure is used, the theoretical basis of which we explained at the beginning of the article: the multiplier increases more strongly only in the cores that perform calculations, while the rest are disabled or very slow. As a result, an application that does not need to use all the cores can run much more efficiently, the processor will not use more power, the thermal output value will not be exceeded, and the cooling system will work without problems. Intel was the first to introduce Turbo Boost technology in its Core i7 9 processors. 00 on LGA 1366. Turbo mode worked quite simply in them, increasing the multiplier of all cores, limited by the maximum TDP value.
00 on LGA 1366. Turbo mode worked quite simply in them, increasing the multiplier of all cores, limited by the maximum TDP value.
The Core i7 800 and Core i5 600 use turbo mode extremely smoothly, but even better in this respect are the latest Intel laptop processors. They used Turbo Boost technology in the master version. As you know they have integrated graphic card and Turbo Boost technology turns on both systems i.e. CPU and GPU. The very scale of clock processors in laptop versions, often up to several tens of percent, is impressive, but Intel went further. In the case of intensive use of the graphics system, the frequency of its operation can also be increased, as a result of which the operating frequency of the cores becomes limited so as not to exceed the maximum TDP value. The processor works perfectly and harmoniously, taking into account not only the need for processing power of the cores, but also the integrated graphics layout. The latest Intel processors perform better because when the core multiplier is increased, inactive cores are completely disabled.
The latest Intel processors perform better because when the core multiplier is increased, inactive cores are completely disabled.
AMD CPUs with Turbo Core
AMD has delayed its response to Intel’s revolutionary idea for a while. Turbo mode in the processors of this company was expected only with the release of the latest six-core Phenom II. The technology is called Turbo Core and is very different from what Intel proposed. While Intel processors turn turbo mode on and off depending on thermal conditions, AMD processors enter it when at least three of the six cores are idle. The frequency of the rest in this case can be increased by a maximum of 500 MHz. This ensures efficient operation and also does not exceed the maximum TDP value. AMD offers extremely easy overclocking with an unlocked multiplier and system-level control of all cores via the OverDrive app.
We looked at how Turbo Boost performance can be realized in practice by testing the Intel Core i5-750 processor. The results showed that overclocking is accelerated primarily by applications that load one or two cores, for example, Apple iTunes converts songs from CDs to MP3 16% faster and movies in Full HD (1920 x 1080 pixels) format supported by the iPod (640 x 352 pixels) 14% faster. Frame rate in 3D Resident Evil 5 increased by 11% after applying Turbo Boost technology.
The results showed that overclocking is accelerated primarily by applications that load one or two cores, for example, Apple iTunes converts songs from CDs to MP3 16% faster and movies in Full HD (1920 x 1080 pixels) format supported by the iPod (640 x 352 pixels) 14% faster. Frame rate in 3D Resident Evil 5 increased by 11% after applying Turbo Boost technology.
PC Mark Vantage benchmark simulates an office environment with multiple applications. A text editor starts, Internet Explorer opens multiple sites at the same time, and Windows Defender scans the system in the background, looking for spyware. Turbo Boost accelerated this test by 6%.
Increasing power consumption after Turbo Boost is enabled shows Cinebench using Maxon Cinema 4D 3D design application. When only one core is loaded, its performance increases by 20% and power consumption by 8%. The more cores used, the less favorable the ratio of performance growth to energy consumption. After loading all the cores, the increase in efficiency and power consumption for each increases by 6%.
How to enable Turbo Boost
Turbo Boost is enabled in the BIOS setup menu, obviously the motherboard manufacturer has provided it with a feature. Information about the menu in which you should look for it (in some cases it is called Turbo Mode) is contained in the motherboard manual. These are mainly Advanced, Advanced CPU Features, Performance or special ones, such as AI Tweaker or MIT, which collect features related to hardware overclocking. The combined performance boost from Turbo Boost technology comes from standard Mark Vantage software and a performance boost from 3D Mark Vantage. You can charge individual processor cores with Cinebench.
Risk of failure
Even today there is no complete certainty of the success of the operation. You can always find a processor where locked cores will be damaged. This manifests itself in many ways, the most obvious being the inability to unlock the core. It can also happen that the kernel starts up but the system is very unstable, or the instability can only be detected after running under heavy load for a long time.