Infrastructure Consolidation: 6 Tips for Success
Search
Updated on:
IT infrastructure consolidation has become a priority for many organizations–and the sluggish economy is accelerating the trend. As economic woes linger, CIOs continue to look for ways to rein in technology components such as servers, storage, desktop computers, networks and mobile devices.
However, like any other big technology initiative, there’s a right way and wrong way to consolidate. Do it the right way, and companies can save money, reduce energy consumption and improve efficiencies. Do it the wrong way, and they might wish they’d never started consolidating in the first place.
Most IT organizations have either launched consolidation projects or plan to initiate them, according to Forrester Research. Nearly 60 percent of 246 IT executives the firm surveyed in August 2007 said they had either completed or were actively executing an IT consolidation effort that involved servers, storage or an entire data center. Another 36 percent said they were considering a consolidation effort. Of those organizations considering an upcoming consolidation, 76 percent said they planned to begin within the next six months. That means that, at this point, almost nine in 10 businesses are knee-deep in consolidation projects.
As can be expected with such a wide-ranging task as infrastructure consolidation, the drivers for those projects vary greatly. Forrester found that the prime motivations for data center consolidation include im-proving operational efficiency, reducing complexity, enhancing operational staff productivity, reducing power costs, addressing disaster recovery inefficiencies, consolidating application workloads onto fewer servers and reducing overall data center costs.
Nevertheless, the study shows that consolidation is no quick-fix project: Nearly half of the survey respondents said they expected their IT consolidation to take between one and two years to complete.
This effort can pay off with significant benefits. Chris Curran, partner and CTO at Diamond Management and Technology Consultants, points to reduced costs due to a standardized technical environment, increased hardware utilization and decreased hardware footprint; increased agility through data center automation; and increased availability through greater uptime and disaster recovery capabilities.
CIOs and industry experts point to several tips and best practices for consolidating IT infrastructure:
Know your applications and understand how they apply to your organization.
“The main point with infrastructure consolidation is that it must be done within the context of an application architecture,” Curran says. “An organization has to know which applications align with the business strategy and direction and which don’t; which should be retired and when; and what kinds of functional gaps exist in the systems.”
With that knowledge, IT executives can plan proactively to retire some applications and consolidate the underlying infrastructure in a coordinated fashion. Without it, they can run into a variety of obstacles, such as unplanned outages or poor system performance in the consolidated systems.
Without it, they can run into a variety of obstacles, such as unplanned outages or poor system performance in the consolidated systems.
Curran says that a Diamond client in the insurance industry conducted massive and successful server and storage consolidation only after it had completed a broad IT strategy project that included setting priorities for its applications and developing an application blueprint.
The IT department of a Diamond client in the financial services sector that was spending more than $30 million per year on storage was asked by business executives what value the firm was getting for that technology–and how costs could be reduced. “At the time, they didn’t have a business-driven set of projects and capabilities related to data, so answering that question was hard,” Curran says. “Consolidation was virtually impossible without shooting themselves in the foot regarding future needs the business might have. (Curran declined to name either client because of his firm’s relationship with them. )
)
Consolidating Infrastructure — Northramp
In many organizations, technical infrastructure, defined generally as server, storage, and networking capability and capacity is deployed on an as-needed basis in response to additional requirements such as the deployment of services, applications or web sites. The frequent result of this organic approach to infrastructure is a data center environment comprised of a wide variety of makes, models, and configurations located in a variety of locations.
Organizations with little or no proactive infrastructure capability or capacity planning often benefit from a targeted effort to consolidate infrastructure while standardizing the platforms used to provide resources. Further, the concurrent implementation of consolidated and standardized planning and administration processes frequently adds business benefits in addition to lowered investment in equipment and support resources. Consolidation of infrastructure frequently enables an organization to:
- Minimize unnecessary investments in over capacity.
- Lower data center related support expenses.
- Optimize the utilization of server, storage, and other resources and implement better capacity planning.
- Improve the leverage of resources and skill sets.
- Reduce downtime and increase service levels through a more flexible operating environment.
- Facilitate the establishment of metrics-based service level agreements.
- Simplify the planning associated with disaster recovery and business continuity planning.
- Reduce individual location-based infrastructure requirements.
The realization of these benefits from infrastructure consolidation often results in immediate and long term savings for IT organizations.
Consolidating Server Infrastructure
The consolidation of server infrastructure can occur across a number of dimensions, with increasing levels of complexity and savings. These are typically represented by several levels of opportunity:
- Consolidating servers that host the same applications.
- Consolidating servers across applications that share common application components, such as databases and other software services that maintain compatible characteristics.
- Consolidating servers that host development or test environments used for application programming or integration.
- Migrating disparate applications to a single platform consisting of a single or reduced set of vendors and server models for the purposes of further consolidation. For example, this activity might include migrating some applications from one flavor of UNIX to another, if supported.
- Leveraging ‘virtual’ environments in which applications run in separate instances of an operating system on a single server using virtualization software from a handful of vendors.
- Consolidating data center locations. This activity might include the closure of multiple data centers and/or ‘server closets’ and the relocation of the infrastructure to a reduced number of locations.
Organizations sometimes face a variety of challenges in implementing the above types of consolidation. For example, an organization’s level of decentralized IT control may limit its ability to accomplish even the simplest of consolidation activities. Additionally bandwidth constraints at one or more remote locations may limit the ability to locate servers off-site. However, in most cases, even level one and some level two activities result in material savings for an organization.
For example, an organization’s level of decentralized IT control may limit its ability to accomplish even the simplest of consolidation activities. Additionally bandwidth constraints at one or more remote locations may limit the ability to locate servers off-site. However, in most cases, even level one and some level two activities result in material savings for an organization.
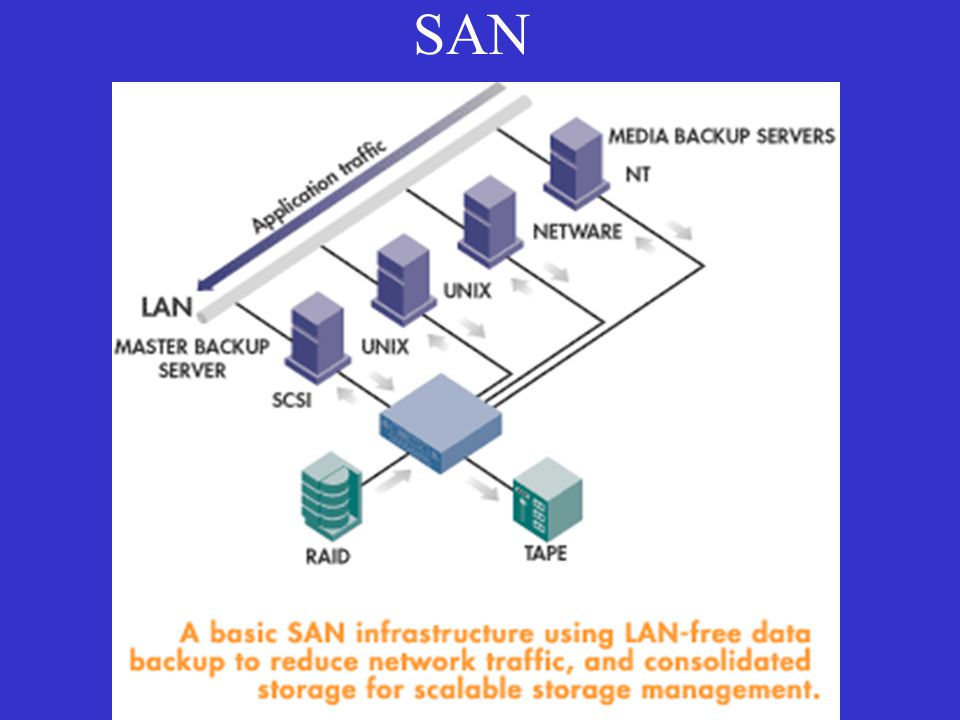
Consolidating Storage Infrastructure
Similar to server environments, storage capacity may also exist independently at various locations and in a variety of forms including disks internal to each server, direct attached storage units, or even multiple storage area networks (SANs). Additionally, tape storage capacity may also exist in a range of internal, direct attached, and network-attached tape libraries.
When storage infrastructure evolves organically over time, different locations or different IT teams frequently address storage needs in disparate ways with solutions acquired from different vendors supplying different technologies.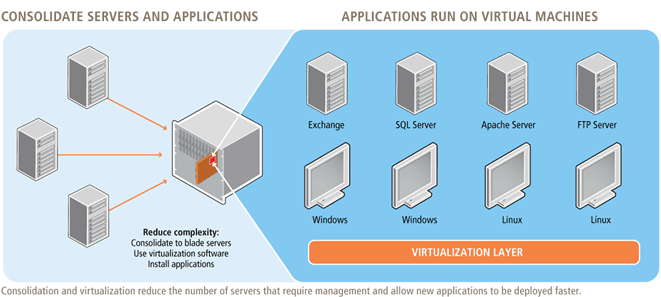 The result is often a growing disparity in storage technologies that further inhibit future opportunities for consolidation and centralized management. In environments such as this, organizations often find themselves continuing to invest in new storage capacity when existing resources already possess sufficient unused capacity, but are too silo’d to be used outside their originally intended purpose.
The result is often a growing disparity in storage technologies that further inhibit future opportunities for consolidation and centralized management. In environments such as this, organizations often find themselves continuing to invest in new storage capacity when existing resources already possess sufficient unused capacity, but are too silo’d to be used outside their originally intended purpose.
The implementation of enterprise-wide hierarchical storage architectures, which addresses both storage infrastructure as well as policy-based data storage guidelines, can significantly reduce the ongoing costs of an organization’s investment in storage and its associated support. The implementation of a new storage architecture however often requires the immediate investment in additional capacity in the form of disk and tape library infrastructure as well as training in the skills necessary to manage a consolidated storage environment.
If implemented successfully however, organizations can realize savings from reduced administration, increased capacity utilization, and the ability to shift less used information to slower, lower cost storage when a tiered architecture is used. Additionally, many organizations that migrate to a consolidated storage infrastructure approach realize additional savings from lower costs associated with data, content, and records management and administration.
Additionally, many organizations that migrate to a consolidated storage infrastructure approach realize additional savings from lower costs associated with data, content, and records management and administration.
Effective storage consolidation requires significant planning, including:
- Inventorying the existing storage footprint to determine the current architectures, technologies, and makes and models in production.
- Capturing current capacity and utilization levels.
- Forecasting three, five, and seven year storage requirements.
- Establishing performance and availability tiers and assigning tiers to application and data types.
- Investing in consolidated, standard storage platforms.
- Consolidating locations with adequate bandwidth and assessing ability to upgrade bandwidth, where required, for additional consolidation.
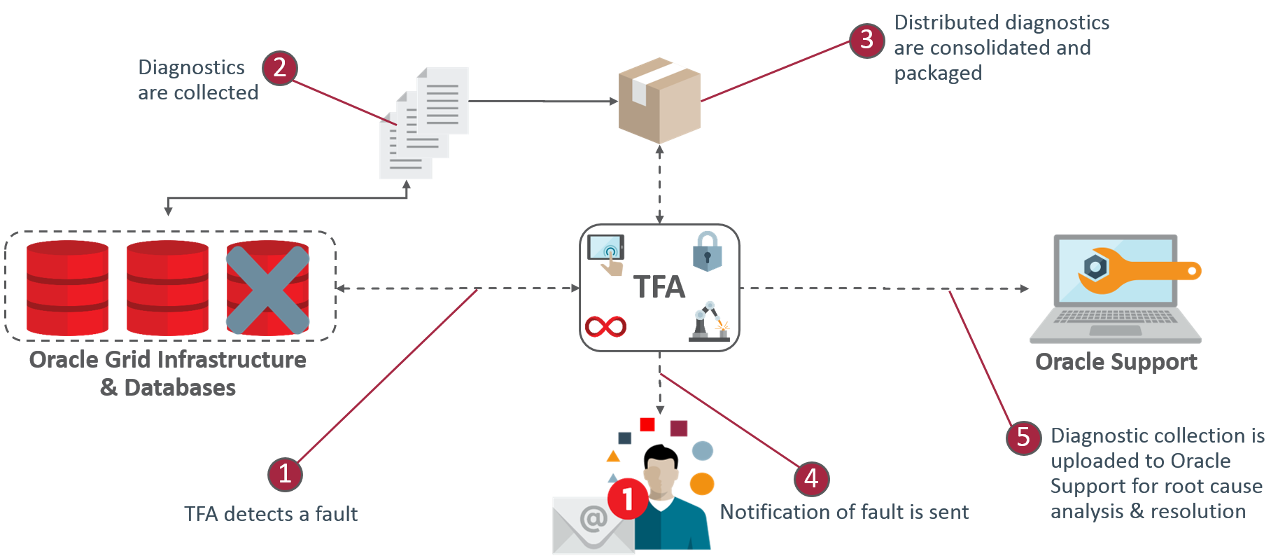
ITSM Help Button. Rapid Incident Diagnosis
Rapid Incident Diagnosis
Effective Incident Root Cause Analysis
Problems Solved
ITSM Help Button Functionality
1.
 Concept
Concept
- collection of the necessary information in a single access point without human intervention
- special tools for quick analysis of collected information
ITSM Help Button (previously Red ITSM Button) is used.
Fig.1.
ITSM Help Button architecture for diagnosing incidents.
Enlarge
In the traditional ITSM organization scheme, all the information necessary to diagnose an incident is collected by the Help Desk staff from different sources:
- user identification data, time and description of the incident — user message by e-mail or phone
- IT infrastructure status information — IT infrastructure management system
- information about user actions — business applications (CRM, HRM, ERP)
- application performance information — application performance management system
2.
 Architecture
Architecture
Client part (installed on the user’s computer):
- EPM-Agent Plus (HelpMe functionality) — interaction with the user, interaction with the server, collecting information about the user and the computer
- SelfTrace working day camera — collection of information about the business application used, the task being performed, user actions, screenshot
- USB device ProLAN-Button (optional) — calling the EPM-Agent Plus
Server :
- Information Aggregator
- SLA-ON Probe — continuous collection of information about the state of the IT infrastructure, the state and performance of business applications
- Consolidated database (optional) — storage of consolidated information collected by the SLA-ON Probe
- SLA-ON Operations Management Console
- Program for automatic import of snapshots of the working day AutoImport
A number of checks are performed on the server and client side.
Back-end tests are performed by the SLA-ON Probe and are called Evaluation Tests . They run continuously and read metrics that evaluate the health of the entire IT infrastructure.
Client side checks are performed by the EPM-Agent Plus and are called Context Checks . They are executed when the «red button» is called and depend on the context (current business application, business operation, task, type of incident, etc.).
When an incident occurs, the support engineer associates information about the state of the IT infrastructure and business applications obtained as a result of the SLA-ON Probe Evaluation Tests with information about the user, user computer and incident received by the EPM Agent with an accuracy of 1 minute Agent Plus and SelfTrace Workday Camera as a result of Contextual Checks .
3. Determining the health of the IT infrastructure at the time of the incident
There are two types of causes for incidents:
- failure of the IT infrastructure and business application
- incorrect user actions
The key element of the architecture for diagnosing incidents of the first kind is the Information Aggregator. The Information Aggregator collects and aggregates information about the health of the IT infrastructure using the SLA-ON Probe and the Consolidated Database.
The Information Aggregator collects and aggregates information about the health of the IT infrastructure using the SLA-ON Probe and the Consolidated Database.
3.1. Operation of the SLA-ON Probe
The function of the SLA-ON Probe is to monitor the health metrics of the IT infrastructure and business applications, which it optionally passes to be written to the Consolidated Database. The results, automatically evaluated on a five-point scale, are called Traffic Lights .
Measurements are carried out automatically using all major network management technologies (SNMP, WMI, Cisco IP SLA, transaction emulation, and others).
A tool for measuring the health status of a particular component of the IT infrastructure is called Expertise (Evaluation Test) . The basic delivery of the SLA-ON Probe already includes more than 50 Expertises prepared by ProLAN.
This eliminates the need for a support engineer or service provider to know in advance which metrics need to be measured to manage the health of a particular component of the IT Infrastructure (leased communication channel, switch, router, etc. ).
).
The Expertise code is open (it is a VBScript program packaged in an XML file), you can easily customize existing Expertises or create new ones.
3.2. SLA-ON Operations Management Console
All SLA-ON Probe results, both raw data and expert judgments (Traffic Lights), are automatically transferred to the SLA-ON Operations Management Console.
Among other things, the SLA-ON Operations console includes two cards: card Cockpit and card HelpDesk (Fig. 2).
The Cockpit is used to display real-time IT infrastructure and business application health information from the SLA-ON Probe and the Consolidated Database.
Map HelpDesk is used to display all significant events, including the list of incidents that have occurred.
Fig.2.
Diagnosis of incidents resulting from failures in IT infrastructure and business applications
Enlarge
Selecting the incident of interest to him on the map HelpDesk and clicking on it with the left mouse button, the support engineer receives full information about what? happened (content of the Snapshot of the Incident).
The support engineer can then right-click on the incident of interest to see why it happened. In this case, he will be automatically transferred to the Cockpit card, where the blue arrow-triangle will show him the health of various components of the IT Infrastructure (network equipment, servers, communication channels, etc.) at the moment when the user pressed the «red button «. If the Traffic Light of some Expertise is red, then the information at the bottom of the screen will show the specialist which metrics have gone beyond the thresholds and by how much.
3.3. Automatic Failure Diagnosis
To automatically diagnose failures, the Assessment Test notification system must be configured so that when an IT Infrastructure failure occurs, the Assessment Test performed by the SLA-ON Probe will automatically report which users (Active Directory group) as a result of this failure may be affected.
This is an important advantage of ProLAN products. When a failure occurs, the SLA-ON Probe automatically extracts the details of such users from Active Directory and attaches them to a message that it sends to Help Desk via SOAP.
Many incidents can be prevented by configuring the SLA-ON Probe to automatically send e-mail messages when IT Infrastructure health or application performance metrics are outside the set values (thresholds).
We call these messages Meaningful Fault Alerts because they can only contain information about which metric went over the threshold, when, by how much, the likely cause of the failure, which users may be affected as a result of the failure, and even what to do in the specified case. This information is displayed on the map HelpDesk where the contents of Incident Snapshots are displayed.
4. Determination of user actions that preceded the incident
Incidents are the result of not only failures of IT infrastructure and business applications, but also incorrect user actions. The definition of user activities in the last 15 minutes, in particular applications, operations and tasks performed by the user, is handled by the application SelfTrace . To automatically import work results SelfTrace AutoImport application must be running on the Information Aggregator.
To automatically import work results SelfTrace AutoImport application must be running on the Information Aggregator.
The following are used to define the business operation:
The appropriate directories must first be created, in which the correspondence between the names of business operations and their characteristics (text in the window title, URL, text on the screen) is specified. Catalogs can be loaded automatically (when the computer is started) and manually, by pressing a special button. Directories can be stored on a web server (HTTP), FTP server, file server.
Having received the name of the operation, SelfTrace uses it as follows:
- when the «red button» is pressed, passes it to the Agent EPM-Agent Plus for inclusion in the Incident Snapshot, which is transmitted to the Information Aggregator and registered in the Service Desk.
 This information is especially important in large companies that use multiple support teams according to products and business operations;
This information is especially important in large companies that use multiple support teams according to products and business operations;
- transfers information to the AutoImport application running on the Aggregator in real time for writing to the database. WMI is used as the information transfer transport.
Thanks to this, the support engineer, having selected the map HelpDesk in the SLA-ON Operations application and clicking on the button History , immediately sees a list of applications, business operations and tasks that the user performed for 15 minutes before pressing the «red button » (Fig. 3).
In addition, the EPM-Agent Plus running on the client’s workstation, after pressing the «red button», performs a number of Context Checks that collect information about the user’s computer, the user himself, if necessary — the nearest network environment, environment variables, etc.
Fig.3.
Displaying the history of user actions in the HelpDesk map of the SLA-ON Operations application
Enlarge
Implementation of the system of financial and economic management of the enterprise in Gazprom StroyTEK Salavat
May 19, 2022
With this project, our team won the 1C: Project of the Year competition.
Regions : Central Federal District of the Russian Federation
Labor costs : 24,500 thousand man-hours
Speed , (arm/month) : 39, 3
Customer Satisfaction : 10 out of 10
Implementation
Assessment of the level of automation before the start of the project (scheme):
Project Implementation Schedule:
Gazprom StroyTEK Salavat moved to a new level of enterprise management thanks to the introduction of end-to-end business processes that linked financial flows and the movement of goods and materials.
The integration between the systems performed by our team eliminated the influence of the human factor on the data in the system. Information is obtained from a single data source for making managerial decisions. Control over finances and costs ensures a reduction in the cost of finished products, which is especially important in times of crisis.
Project goal
Transition of Gazprom StroyTEK Salavat JSC to a modern integrated information system for management, regulatory and tax accounting, automation of the main production and auxiliary business processes in all areas of the enterprise and reduction of time and labor costs when obtaining management and corporate reporting.
Project objectives
- Ensure the maintenance of regulated and tax accounting in accordance with the requirements of the current legislation
- Provide centralized procurement management
- Provide strategic and operational sales planning
- Provide centralized management of production
- Provide centralized cost management and calculation of the cost of finished products
- Ensure accounting of personnel and payroll in accordance with the requirements of current legislation
- Ensure the automation of the Treasury system
- To provide automation of the Budgeting system;
- Provide integration with «1C: Document Management» and Service Desk
- Ensure standardized accounting of operations in the context of the required analytical features
- Agree, describe, standardize and implement internal and external reporting forms
- Train users on how to use the new system
- Train the IT specialists of the company in the skills of modifying the functionality of the system, which will further adapt the information system to changing business requirements
Project results
As a result of the project, an automated system for financial and economic management of the enterprise’s economic activity was introduced based on 1C: ERP software products. Holding management and 1C: Salary and personnel management 8 CORP. It was possible to achieve the following tasks:
Holding management and 1C: Salary and personnel management 8 CORP. It was possible to achieve the following tasks:
- Due to the elimination of double entry of information, manual labor is minimized
- The level of automation of the company in all areas of activity has increased significantly
- Automated reduction of costs and terms of preparation of management and regulatory reporting
- Increased reliability of information and reduced the risk of errors
- The quality of management has improved due to the efficiency of obtaining information for decision-making, the reliability of the information received has been increased
- The terms of the budget program were reduced, the accuracy of the forecast was increased due to the high degree of automation of budgeting
- An optimal production plan has been built, taking into account limited resources and available production capacities
- Reduced delivery times for finished products by improving the quality of planning
- Purchasing activity was optimized using the available resources of the enterprise
- Reduced paperwork
- Accounting and monitoring of the fulfillment of contractual obligations is regularly carried out
- Implemented integration with related information systems
- Transferred historical data necessary for the operating activities of the company
Implemented software products
1:ERP. Holding management :
Holding management :
- Regulated accounting
- Financial management and budgeting
- Centralized Treasury
- Purchasing management
- Sales Management
- Warehouse and Inventory Management
- Production management
- Management reporting
- Cost management and costing
- Contract activities
- Integration with external systems
- CISR
1C: Payroll and personnel management CORP :
- HR records management
- Calculation of salary of employees
- Labor protection
- Recruitment and personnel management
- Integration with 1C: Document Management
- Integration with ACS
1C: Document flow KORP :
- Electronic Archive
1C: Corporate tool package :
- Performance Center
Solution architecture
Functional architecture of the resulting solution:
The complex financial management information system is implemented on a classic three-level architecture: client part, application server, database server. To manage the processes of implementation and development of configurations based on 1C:Enterprise 8.3 CORP, several environments are organized:
To manage the processes of implementation and development of configurations based on 1C:Enterprise 8.3 CORP, several environments are organized:
- Development environment — for developing new functionality in 1C configurations
- Testing environment – designed to test the developed functionality and perform load testing
- Production environment — designed for industrial operation of the system.
When building a technical architecture in a production environment, all servers (with the exception of Web servers) are aimed at serving exclusively “1C: ERP. UH», «1C: ZUP», «1C: Document Management».
The technical architecture with access through the terminal server is represented by several servers, which are divided according to their functionality:
- Database Server (DS)
- Application server 1C (AS)
- Terminal Access Server (TS)
- Web Server (WS)
Servers are hosted both on virtual machines and on physical servers.