Asus Multicore enhancement — auto, enabled or disabled? : overclocking
-9700k cpu, base clock 3.6ghz, boosts up to 4.9ghz, cooled by Be quiet Shadow Rock Slim
-Asus Strix z390-e motherboard
-DDR4 ram overclocked to 3200mhz via XMP.
I have recently updated my bios after also changing my 8 year old bronze psu with a platinum (both at 750w).
Before upgrading the PSU, clock speed during gaming, according to MSI afterburner on-screen display (or RTSS, whatever) would keep itself at 3600mhz and while on desktop it would boost up to 4700mhz for short periods of time. Temps were keeping themselves laughably low, around 57 to 64 degrees on load (66 tops on 100% load on furmark’s cpu burner stress test).
After installing the new PSU I noticed a new max clock speed @ 4900mhz, however I’m still not sure if it’s simply because I have a more competent psu or because of the new bios version. I updated bios yesterday and changed the psu 2 days ago and have also been busy with work, so I didn’t get to test things separately during gaming. I only noticed that MSI AB charts were showing peaks of 4900mhz, which I never noticed until this point.
Today I started gaming a few hours while also checking OSD stats for clock speed and temps and this time my clock reading would keep itself only at 4700mhz, but temps would range between 75-80. The temp range freaked me out, because I’m trying to stay away from 70+ temp ranges, since such temps might age the cpu prematurely (just my assumption; please clarify if cpu’s can last just as long around these temps, but I’m sure anything above 80 is never recommended IIRC). So I was wondering if I accidentally overclocked my cpu while readjusting bios settings to the ones I had before updating it and went back to it’s settings.
It’s the first time I discover «Multicore enhancement», which apparently was set to «Auto» since the bios update, meaning that BIOS would force ALL my cores on a turbo 4.7ghz. With only 20-30% cpu loads (hardly ever passing 35%) during my gaming sessions, I also didn’t notice any performance improvement (or maybe there was an improvement, just not big enough to catch my eye).
After I read a bit about MCE forcing all cores to go turbo max, I decided to keep it disabled, but I have no real clue about what is better for my system. Even with MCE disabled, my cpu still reads 4700mhz during gaming, but this time i have mid-high 60s to low 70s temp ranges and seems to run just as smooth.
_____________TL;DR_________________
I really don’t know what I’m doing with the MCE options. Manual doesn’t clarify much and youtube videos seem to have only 2 options instead of 3, like in my case. The 3 options I have are:
— Auto — let BIOS optimize performance
— Disabled — enforce all limits
— Enabled — remove all limits
So what should I do? Descriptions sound too confusing. Iv’e currently set it on disabled. I don’t wanna deal with high temps that could age my cpu prematurely. I just want good performance only when it’s necessary, but definitely don’t wanna turn my cpu into a furnace.
Also, please let me know if I have to do other bios settings for the MCE setting you suggest.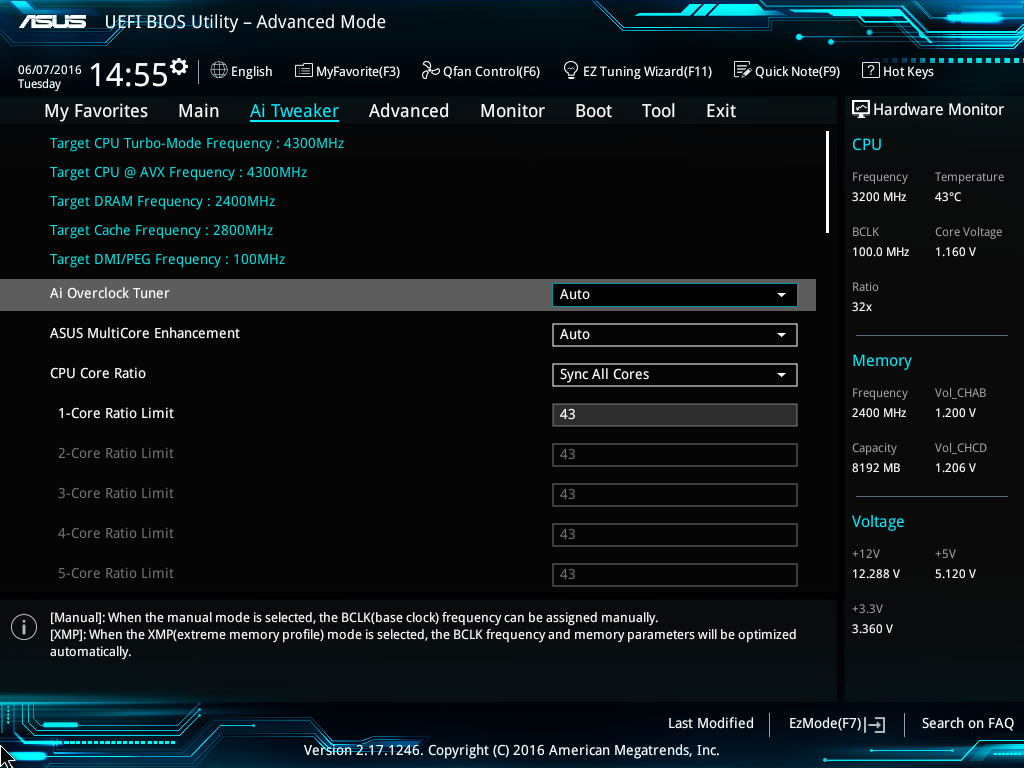
Update: MCE currently set to disabled and I went away like 40 mins to do some stuff and left it on sleep. Woke it up at 35 idle temp (the lowest I know it can go) and gave it a Furmark CPU burn test. It started with the boosted 4900mhz, temp started rising kinda quick up till 74. Once it hit 74-75, it downclocked a bit to 4400mhz, but temps now stabilized @ 71 and 4400mhz. I guess that’s ok so far, but I’m still open to some tips.
Impact of MultiCore Enhancement (MCE) and Long Power Duration Limits on Thermals and Content Creation Performance
Read this article at https://www.pugetsystems.com/guides/2375
Written on October 20, 2022 by Matt Bach
Share:
Table of Contents
- Introduction
- Test Setup
- Core i9 13900K MCE and P1P2 Limits: Performance
- Core i9 13900K MCE and P1P2 Limits: CPU Temperature
- Is MultiCore Enhancement and Unlocked Power Limits Worth it for Content Creation?
Introduction
With the new 13th Gen processors, Intel has given us a great boost to performance across the board. However, one of the main criticism people have had with these CPUs (and with AMD’s Ryzen 7000 series) is how hot they get under load.
However, one of the main criticism people have had with these CPUs (and with AMD’s Ryzen 7000 series) is how hot they get under load.
Over the years, we have repeatedly had to deal with motherboard manufacturers deciding to configure the BIOS to overclock the CPU by default, without doing much to warn the user about what they are doing. In fact, you can go all the way back to 2017 when we posted an article discussing how many motherboard manufacturers made the decision to default to enable a feature called «MultiCore Enhancement» which allowed the CPU to run at the maximum turbo frequency regardless of how many cores were being used.
For a while, things improved and motherboards defaulted to disabling this kind of automatic overclocking. But recently, this behavior has been making a resurgence. We saw this just recently with the AMD Ryzen 7000 series, where disabling two settings in the BIOS (Core Performance Boost and Precision Boost Overdrive) resulted in a 30C drop in CPU temperatures, with minimal impact on performance.
On Intel, the story is much the same, with just a difference in the specifics. In the case of the ASUS Z690 motherboards we are currently using for the 12th and 13th Gen Intel processors, there are three main settings that allow the CPU to be overclocked by default:
- MultiCore Enhancement (MCE) allows the CPU to run at the maximum turbo frequency on all cores, regardless of how many cores are in use. Typically, the boost frequency varies based on how many cores are being used.
- Long Duration Package Power Limit (P1) defines the maximum wattage the CPU is allowed to run when under sustained loads. By default, this is set to 4095W (unlimited), whereas Intel’s spec is 125W for the new 13th Gen CPUs.
-
Short Duration Package Power Limit (P2) is similar to the P1 power limit, but is a secondary wattage that the CPU is allowed to hit for short bursts. By default, this is set to 4095W (unlimited), whereas Intel’s spec is either 181W (13600K) or 253W (13700K/13900K)
As a workstation system integrator, we almost always prefer to run hardware at reference speeds in order to maximize reliability. Over the years, we have had some success convincing motherboard manufacturers to stop overclocking by default, but recently it has been a losing battle. And now that we are seeing similar behavior on AMD Ryzen platforms, we have fairly low expectations that this will change anytime soon.
Over the years, we have had some success convincing motherboard manufacturers to stop overclocking by default, but recently it has been a losing battle. And now that we are seeing similar behavior on AMD Ryzen platforms, we have fairly low expectations that this will change anytime soon.
The question we want to answer is twofold: What kind of performance are we giving up by disabling this auto-overclocking, and what impact does it have on CPU temperatures? If the performance drop is large and the CPU temperatures are not affected much, we may have to reevaluate our stance on these settings in both our article testing and workstation sales. On the other hand, if the performance drop is minimal, but the CPU temperature drops significantly, that reinforces our view that (again, for us as a workstation manufacturer) it is better to disable these auto overclocking settings.
Looking for a Content Creation Workstation?
Puget Systems offers a range of powerful and reliable systems that are tailor-made for your unique workflow.
Configure a System!
Labs Consultation Service
Our Labs team is available to provide in-depth hardware recommendations based on your workflow.
Test Setup
Listed below are the specifications of the systems we will be using for our testing:
| Benchmark Software | |
| Benchmark | PugetBench for After Effects 0.95.2 (After Effects 22.4) PugetBench for Premiere Pro 0.95.5 (Premiere Pro 22.6.1) PugetBench for DaVinci Resolve 0.93.1 (DaVinci Resolve Studio 18.0.2) PugetBench for Photoshop 0.93.3 (Photoshop 23.5) PugetBench for Lightroom Classic 0.93 (Lightroom Classic 11.5) |
*Latest drivers, OS updates, BIOS, and firmware as of September 14th, 2022
To see how MCE and the P1/P2 power limits affect performance and CPU temperatures, we are going to focus on the recently released Intel Core i9 13900K processor. For the CPU cooling, we will be using two different CPU coolers: our go-to standard Noctua NH-U12A 120mm air cooler, as well as the Fractal Celsius+ S28 Prisma 2x140MM AIO liquid cooler. We almost exclusively use air coolers in our workstations, but we wanted to be sure that we were not leaving performance on the table due to thermal throttling.
For the CPU cooling, we will be using two different CPU coolers: our go-to standard Noctua NH-U12A 120mm air cooler, as well as the Fractal Celsius+ S28 Prisma 2x140MM AIO liquid cooler. We almost exclusively use air coolers in our workstations, but we wanted to be sure that we were not leaving performance on the table due to thermal throttling.
All of our testing is done on an open-air test bed in order to remove the chassis airflow from the equation. We want to drill down on these auto-overclock settings and remove as many other variables as possible. With that goal in mind, we also set the CPU fan to run at 100% so that the fan ramping profiles wouldn’t come into play.
For the tests themselves, we will be primarily using our PugetBench series of benchmarks using the latest versions of the host applications. Most of these benchmarks include the ability to upload the results to our online database, so if you want to know how your own system compares, you can download and run the benchmark yourself. Our testing is also supplemented with a number of benchmarks directly from the software developers for applications like Cinema4D and V-Ray.
Our testing is also supplemented with a number of benchmarks directly from the software developers for applications like Cinema4D and V-Ray.
Core i9 13900K MCE and P1P2 Limits: Performance
In the chart above, we tested with MultiCore Enhancement (MCE) set to auto/enabled/disabled, and with the P1/P2 power limits either disabled or manually set to match Intel’s specifications for the Core i9 13900K. Most of the testing was done with the Noctua 120mm cooler, but we also did a round of testing with MCE enabled and the power limits left open using the Fractal 2x140mm AIO liquid cooler in order to see if having additional cooling power would impact the results.
On the whole, we were a bit surprised at how little of an impact these overclock settings made. All of our photo and video editing benchmarks saw virtually no difference in performance. The largest variance for these applications was just 3%, which is within the margin of error for this kind of real-world testing. Even the CineBench single core and compiling shaders in Unreal Engine tests were largely unaffected.
Even the CineBench single core and compiling shaders in Unreal Engine tests were largely unaffected.
The three cases that did see a difference were Cinebench multi-core (10 minute run), V-Ray in CPU mode, and building lighting in Unreal Engine, but in very different ways. V-Ray and Cinebench saw an 8-16% performance drop when we switched MCE from «Auto» to «Disabled» and enforced the power limits.
Build lighting in Unreal Engine, however, only saw a performance boost when we switched MCE from «Auto» to «Enabled». Apparently, for this type of workload, the motherboard is not overclocking the CPU much when MCE is just on auto, so it needs to be forced on in order to see an increase in performance.
As for the Fractal 2x140mm AIO liquid cooler, it appears to make no difference in terms of performance. We will again note that we are in an open-air test bed and that results may be different in an enclosed chassis. But for this set of performance testing, the Noctua 120mm cooler seems to be plenty adequate.
Basically, this means that the biggest performance impact these overclock settings tend to make is on highly threaded workloads. The biggest difference was Cinebench which had about a 20% performance swing, while others were closer to 10-15%. For the rest of our workloads (photo and video editing), performance was largely unchanged.
This brings us to our second question: how much do these settings impact the CPU temperature?
Core i9 13900K MCE and P1P2 Limits: CPU Temperature
To look at how much MultiCore Enhancement (MCE) and the P1/P2 power limits increase the CPU temperature, we decided to chart out the hottest core reading over the course of our entire automated benchmark run. This makes it a bit harder to read overall than it would be if we broke it down to something like «max CPU temperature in application X», but a lot of our workloads are fairly «burst-y», and there are nuances we would miss out on if we simplified things too much. Since the benchmark run is a bit long, we decided to split the benchmark run in half and plot it across two charts. We highly recommend clicking on the charts above so you can view the full-sized images.
Since the benchmark run is a bit long, we decided to split the benchmark run in half and plot it across two charts. We highly recommend clicking on the charts above so you can view the full-sized images.
On the whole, disabling MCE and enforcing the power limits has a bit of a mixed impact on CPU temperatures. Unlike what we saw with PBO and CPB on Ryzen 7000, most of the applications where performance was largely unaffected by these settings didn’t see much of a change in CPU temperatures. On the other hand, Unreal Engine saw as much as a 30C drop, and the sustained CPU temperature during Cinebench was almost 30-40C lower depending on which settings you compare it to.
In other words, in exchange for a 10-20% drop in performance in highly threaded tasks, we see around a 30-40C drop in CPU temperature. Whether that is worth the tradeoff is going to be something people will have to decide for themselves. We tend to lean towards stability and reliability over performance, but if you are comfortable with your CPU hitting 100C during these kinds of loads, it is also perfectly fine to go in that direction.
One last thing to note is that the Fractal 2x140mm AIO liquid cooler made a small, but noticeable impact on CPU temperature. It would likely be a bit more if we did this testing in an enclosed chassis, but under sustained heavy load, we saw anywhere from a 5-10C drop in CPU temperature compared to the Noctua 120mm cooler. It is worth repeating, however, that performance was no different with the AIO cooler.
Is MultiCore Enhancement and Unlocked Power Limits Worth it for Content Creation?
In most of the workloads we tested, having MultiCore Enhancement (MCE) enabled and the P1/P2 power limits unlocked didn’t have much of an impact on either performance or CPU temperatures. The few times where it did cause an impact were highly threaded, CPU heavy, tasks like CineBench and V-Ray CPU rendering, and building lighting in Unreal Engine.
In these cases, disabling MCE and locking the P1/P2 power limits to match Intel’s official specifications for the Core i9 13900K resulted in around a 10-20% drop in performance. In exchange, however, the CPU temperature dropped by a massive 30-40C. In other words, you can get a significant increase in performance (about the same as going one «model» up in Intel’s product line) with these settings in their default configuration, but you pay for it with much higher power draw and CPU temperatures. This makes sense on the surface, but it is worth pointing out that similar testing we recently did with the AMD Ryzen 9 7950X showed a massive increase in CPU temperature across the board with auto overclocking, even when performance wasn’t impacted.
So, should you disable MCE and set the P1/P2 power limits to match Intel’s specifications? To be honest, for most users it likely won’t matter at all. CPU-based rendering is rapidly being replaced with GPU-based equivalents, and if your workflow is dependent on a CPU rendering engine, you are likely already investing in something like Threadripper PRO or Xeon W. There will be niche situations like game developers building lighting in Unreal Engine, but most of the primary use-cases for Intel Core processors are going to be completely unaffected.
We are going to continue to disable MCE and enforce the P1/P2 power limits in our testing and workstations, but we want to make it clear that there is no right or wrong answer here. It is just a matter of tradeoffs, and the 30-40C temperature increase simply does not constitute an acceptable tradeoff for us as a workstation system integrator.
Looking for a Content Creation Workstation?
Puget Systems offers a range of powerful and reliable systems that are tailor-made for your unique workflow.
Configure a System!
Labs Consultation Service
Our Labs team is available to provide in-depth hardware recommendations based on your workflow.
Tags: Photoshop, After Effects, Lightroom CLassic, DaVinci Resolve, Premiere Pro, V-Ray, Cinebench, i9 13900K, MultiCore Enhancement
Support for multi-core processors in embedded systems | open systems. DBMS
The eyes of leading players in the IT industry are increasingly turning to multi-core processors, and for good reason — compared to traditional integrated circuits, they provide more processing power through parallelism, offer better system organization, and also operate at lower clock speeds.
The eyes of leading players in the IT industry are increasingly turning to multi-core processors, and for good reason — compared to traditional integrated circuits, they provide more processing power through parallelism, offer better system organization, and also operate at lower clock speeds. Effective use of multi-core technology can improve the performance and scalability of embedded applications.
The transition to multi-core processors is proceeding at a rapid pace, and multi-core processors have already taken center stage in the product lines of leading semiconductor vendors, offering chips ranging from two to eight cores.
Multi-core technologies can have some impact on system designers and programmers who have extensive experience in single-processor architectures but little expertise in multi-processing configurations. For example, when managing shared resources in a multi-core chip, when each core has a separate L1 cache, while simultaneously separating the L2 cache, memory and interrupt subsystems, and peripherals (Figure 1), the system designer must provide each core exclusive access to certain resources and ensure that applications running on one core do not access resources destined for another core.
| Fig. 1. Structure of a typical multi-core processor |
The presence of multiple cores can lead to increased development complexity associated with connecting additional mechanisms and making changes to the source code developed for single-core architectures. For example, to communicate with each other, applications running in different cores may require the use of effective inter-task communication mechanisms (Interprocess Communication, IPC), data infrastructure in shared memory, as well as basic synchronization elements to protect shared resources. Porting code is also a problem.
Multiprocessing modes and RTOS
The operating system chosen for a multi-core architecture can have a significant impact on the complexity of solving problems associated with multi-core technologies, but much will depend on whether the OS supports the various multiprocessing modes provided by the multi-core microprocessor. These modes are characterized by three main implementations:
- asymmetric multiprocessing (AMP) — a separate OS or an individual image of one OS runs on each processor core;
- symmetric multiprocessing — a single OS image simultaneously manages all processor cores, and applications can use any core;
- exclusive multiprocessing — a single OS image simultaneously manages all processor cores, but each application is assigned to a specific core.
Asymmetric multiprocessing
Asymmetric multiprocessing provides an execution mode similar to that used in traditional uniprocessor systems, which is well known and understood by most developers. Therefore, this mode offers a relatively easy way to port existing code. It also implements a direct mechanism for keeping track of how CPU cores are being used. Finally, in most cases, the mode allows developers to use standard debugging tools and techniques.
Asymmetric multiprocessing can be either homogeneous — each core runs the same type and version of the operating system, or heterogeneous — the cores run on different operating systems or different versions of the same OS. In a homogeneous runtime environment, developers can use multiple cores by choosing an OS that supports a distributed programming model, such as QNX Neutrino. Installed on the target system, this model allows applications running in one kernel to transparently interact with other applications and system services (for example, device drivers and protocol suites) of other kernels, but without the significant CPU load associated with traditional forms of intertask communication.
A heterogeneous runtime environment has slightly different requirements. In this case, the developer must either implement his own communication scheme, or choose two operating systems that have a common infrastructure (probably based on the IP protocol) for interprocessor communication. To avoid resource conflicts, such operating systems must also provide standardized mechanisms for accessing shared hardware components.
Here is an example of using a heterogeneous environment: one core processes the input traffic from the hardware interface, and the other is responsible for processing outgoing traffic. Since the traffic is represented by two independent streams, there is no need for two cores to interact and exchange data with each other. As a result, the operating system does not have to provide a mechanism for intertask communication between cores. Despite this, it should guarantee the real-time performance needed to handle the traffic flows.
There is another example of using a homogeneous environment, in which two cores work with a distributed control panel, with each core accessing different parts of the dashboard. To properly manage the dashboard, applications running on multiple cores must operate in a consistent fashion. To implement this consistency, the OS must provide robust support for intertask communication mechanisms, such as a shared memory infrastructure for routing table information.
| Fig. 2. Using Promiscuous Asymmetric Multiprocessing (AMP) for Control Panel and Dashboard Modes |
In the heterogeneous runtime example shown in Figure 2, one core implements the control panel while the other handles all traffic coming from the dashboard, which means real-time performance. In this case, both operating systems running on two cores must support a sequential mechanism for intertask communication, for example, the Transparent Inter-Process Communication Protocol with the «transparency» property. The protocol allows kernels to communicate through the possible use of shared structures and is the standard for interoperability between dissimilar operating systems in a networked environment. Compared to TCP/IP, this protocol is faster and more efficient, eliminates message loss, and supports many more features that are used in next-generation network devices.
In virtually all cases, the operating system’s support for underlying and easy-to-use communication protocols can improve inter-kernel communication. In particular, an OS built with a distributed programming paradigm can take advantage of the parallelism provided by multiple cores. The most common operating systems that support AMP are hard real-time systems such as VxWorks, OSE, and QNX, but some real-time implementations of Linux now have this functionality.
Resource allocation
With asymmetric multiprocessing, the application developer has the ability to determine how the shared hardware resources used by applications will be distributed among the cores. This typically happens statically during the boot process and includes physical memory allocation, use of peripherals, and interrupt management. If the system can allocate resources dynamically, then this will entail complex coordination between the cores.
The specifics of asymmetric multiprocessing is such that the processes of each OS will always run on its own core, even if other cores are in a waiting state. As a result, one core may be underutilized or significantly overutilized. In order to solve the problem of such states, the system can allow applications to move dynamically from one core to another. This path, however, may involve the introduction of complex checkpoints to check state information or possible service interruptions when the application is stopped on one core and resumed on another. Also, porting is quite difficult, and sometimes even impossible, in cases where different operating systems are running on the cores.
Symmetric multiprocessing
Resource allocation in a multi-core architecture can be difficult, especially when many software components have no knowledge of how other components use those resources. Symmetric multiprocessing (SMP) offers the execution of only one OS in all cores of the system. Since the OS has the ability to influence the operation of all system elements at any given time, it can allocate resources across multiple cores with little or no application developer intervention. Moreover, an OS can support built-in standardized operations that allow multiple applications to share resources safely and easily. Symmetric multiprocessing is commonly used in desktop and server operating systems.
By running only one OS, you can dynamically allocate resources between special applications, but not between CPU cores, thus making more efficient use of available hardware. It also allows system tracing tools to collect statistical information about the execution and interaction of applications at the multi-core system level as a whole, helping developers to correctly understand the optimization and debugging of applications. For example, the system profiler of the QNX Momentics SDK can track transitions of control flows from one core to another, as well as the use of basic OS functions, scheduling events, messaging between applications, and other events using high-resolution timestamps. Application synchronization also becomes much easier because developers can use basic OS functions instead of complex inter-task communication mechanisms.
A properly implemented OS that supports symmetric multiprocessing provides these benefits without forcing the developer to use specialized application programming interfaces or programming languages. For a long time, developers have been using the POSIX pthreads API on high-end symmetric multiprocessing systems. The POSIX standard allows developers to write code that can be used on both single-processor and multi-core systems. In fact, some operating systems (such as Linux, Solaris, QNX) allow the same source code to be used when running on any type of processor.
Well-designed symmetric multiprocessing operating systems such as Windows, Solaris, QNX Neutrino allow threads of control within an application to run concurrently on any core. This parallelism provides applications with the full processing power of the processor at any given time. If the OS provides appropriate preemption and thread prioritization capabilities, it can help the application developer ensure that processor cycles are allocated to those applications that need it most.
In the control panel script shown in Fig. 3, symmetric multiprocessing allows all threads of control belonging to different processes to run on any core. For example, a Command-Line Interface (CLI) process might be running while a trace application is performing intensive calculations.
| Fig. 3. Using Symmetric Multiprocessing in Control Panel |
Exceptional multiprocessing
Bound Multiprocessing (BMP) is a new mode introduced by QNX Software Systems that retains the benefits of a transparent symmetric multiprocessing resource manager and allows developers to bind software tasks to specific cores. As in the case of symmetric multiprocessing, one copy of the OS retains a complete view of all system resources, allowing them to be dynamically allocated and shared among applications. However, during application initialization, a system developer-defined setting can force all of the application’s control flows to run on the specified core only.
Compared to the full «floating» mode of symmetric multiprocessing, this approach provides several advantages. It eliminates cache overflows that can degrade the performance of symmetric multiprocessing systems by allowing applications that share the same set of data to run exclusively on a single core. It also offers faster debugging of applications compared to symmetric multiprocessing, since all threads of control running within the same application run on the same core. Finally, it helps legacy applications designed for uniprocessor systems run correctly by allowing them to run on a single core.
When using exclusive multiprocessing, an application locked to one core cannot use other cores, even if they are idle. The OS developer can provide tools to analyze the resource usage (including CPU usage) of each application and recommend the best way to distribute applications across cores for maximum performance. If the OS also allows you to dynamically change the assigned processor core using an additional microprocessor, then the user gets the ability to dynamically switch from one core to another without additional checkpointing and stopping/restarting the application.
|
Fig. |
In the example shown in fig. 4, the system with exclusive multiprocessing operates in half-duplex mode. The receiving process with multiple threads of control runs on core 0, and the sending process, which also has multiple threads, runs on core 1. This approach saves developers from the tedious task of collecting information for each core and combining it for later analysis.
In the example shown in fig. 5, control panel applications (command line interface; operation, administration, and maintenance; dashboard management) run on core 0, while input and output dashboard applications work together on core 1. Developers can implement an inter-task communication (IPC) mechanism ) for this scenario using local OS mechanisms or synchronized protected shared memory structures.
|
Fig. |
Between asymmetric and symmetric multiprocessing, exclusive multiprocessing offers an effective porting strategy for users planning to move to full symmetric multiprocessing, but who are concerned about the performance of existing code in the current parallel execution model. Users can port existing code to a multi-core processor and merge it initially on a single core to ensure proper functionality.
By associating applications (and possibly individual threads) with specific cores, developers can also identify potential concurrency issues at the application and thread level. Solving these problems will allow applications to run completely concurrently, thereby maximizing the performance gains provided by multi-core processors.
Selection question
Should a developer choose asymmetric, symmetric, or exclusive multiprocessing?
Asymmetric multiprocessing works well with existing applications, but has limited scalability beyond two cores. Symmetric multiprocessing offers transparent resource management, but may not work with software designed for uniprocessor systems. Exceptional multiprocessing offers the same benefits as symmetrical multiprocessing, but allows single-processor applications to run correctly, making porting existing software much easier. As shown in table , the flexibility to choose any of these models allows developers to achieve the optimal balance between performance, scalability, and ease of portability.
Andrey Nikolaev ([email protected]) — Development Director at SWD Software (St. Petersburg).
Performance Improvement — Key Collector
When working with a program, there is a desire to get maximum performance when performing tasks. Looking ahead, we want to describe ways to improve performance.
Program launch time
The program is modular, and at startup it loads all available and activated modules by the user, loads their settings and implements them into the interface.
You can significantly reduce the program startup time and overall performance when performing basic operations when working with phrases, if turn off obviously unnecessary modules in « Settings — Modules » . Changes will take effect after restarting the program.
We advise you to turn off only those modules whose functions you absolutely do not plan to use, because the process of enabling and disabling modules is rather inconvenient (requires a restart). And the goal of optimization is not to complicate the work with the program, but, on the contrary, to make it faster.
Opening and closing a project
A program project file is an archive with a database inside. Each time a project is opened, the program unpacks the contents of the archive into a special temporary directory, and each time it is closed, it packs the files into the original archive. Such a system allows you to save disk space at the same time and provides security in the event of an emergency shutdown of the program or PC failure (because the data is already saved in temporary storage).
When working with large projects, the process of unpacking and packing can take a long time. In « Settings — Interface — Project » you can choose to prioritize performance or saving disk space: the lower the compression ratio, the faster the packing and unpacking, and the more space the file takes up on the disk.
If you do not have a lot of disk space, but still work with large projects, and the stage of opening / closing projects has time to tire, you can use the project close mode without packing changed data into the original project file. To use it, you must hold down the key Ctrl when closing the project and confirm the operation in the pop-up window.
Working with a data table
Most of the time we work with data in a project: switch between groups, use filters, sort, copy and paste phrases. You can reduce the execution time of such operations if you hide unnecessary columns .
Simply hiding columns manually or using the automatic column visibility tool does not solve problem . the program expects that at any time you can change your mind and return the column to its place. However, if in «Settings — Parsing — Data table » «enable the option « Optimize phrase loading » , then the program will not load data for hidden columns until the next update of the table ( F5 or manual or forced table update).
If you do not often manually hide and return columns, but mainly work with certain data saved in the template, or use the button for automatically setting the visibility of columns, then using this option will generally slightly increase the speed of the interface response.
Another important optimization is temporarily disabling loading of cell color data into color markers for phrases in the table. You can enable or disable this mode in the lower right corner of the program window. You can also adjust the effect of using this mode in the context menu.
General performance information
Some users are wondering which PC features have the biggest impact on program performance. Therefore, we want to explain the basics using the Key Collector as an example (performing other tasks is not included in the description below!).
Do not take this section as a guide to action. Consult with a technical specialist before making decisions on the purchase of hardware.
When working with the program, 3 types of tasks are performed: parsing, working with data, data analysis.
Parsing (even multi-threaded) is not a difficult task for modern processors. Even a mid-budget model can handle dozens or hundreds of threads with relative ease. most of the time the process is idle (waiting for a response from the server, from the proxy, or a delay between requests). In this regard, it makes little sense to buy the most powerful and most multi-core server processor on the market just for the Key Collector, and not for your other tasks.
When you switch between groups in a project, use filters, sort, mark, copy or move phrases, data is read/written to the project. Unfortunately, this process is often single-threaded, so the dependence on CPU power is non-linear here. Much more important is the speed of the disk. A fast SSD drive can give a significant boost to the speed of the program. Confident PC users may also consider using a RAMDisk, but this is only justified for a very narrow range of tasks, so we will not dwell on this in detail.
Finally, data analysis is the only area of tasks that can take up processor resources. Some phrase grouping and search algorithms are multi-threaded, and here the presence of a powerful CPU gives an advantage. However, after the calculation stage, the stage of writing data to the project begins, therefore, here, too, the speed of the disk will greatly affect the final result.
In other words, it does not make sense to purchase the most powerful computer to use the program.