What specifically are wall-clock-time, user-cpu-time, and system-cpu-time in Unix?
Asked
Modified
19 days ago
Viewed
110k times
I can take a guess based on the names, but what specifically are wall-clock-time, user-cpu-time, and system-cpu-time in Unix?
Is user-cpu time the amount of time spent executing user-code while kernel-cpu time the amount of time spent in the kernel due to the need of privileged operations (like I/O to disk)?
What unit of time is this measurement in?
And is wall-clock time really the number of seconds the process has spent on the CPU or is the name just misleading?
- unix
- operating-system
1
Wall-clock time is the time that a clock on the wall (or a stopwatch in hand) would measure as having elapsed between the start of the process and ‘now’.
The user-cpu time and system-cpu time are pretty much as you said — the amount of time spent in user code and the amount of time spent in kernel code.
The units are seconds (and subseconds, which might be microseconds or nanoseconds).
The wall-clock time is not the number of seconds that the process has spent on the CPU; it is the elapsed time, including time spent waiting for its turn on the CPU (while other processes get to run).
6
Wall clock time: time elapsed according to the computer’s internal clock, which should match time in the outside world. This has nothing to do with CPU usage; it’s given for reference.
User CPU time and system time: exactly what you think. System calls, which include I/O calls such as read, write, etc. are executed by jumping into kernel code and executing that.
If wall clock time < CPU time, then you’re executing a program in parallel. If wall clock time > CPU time, you’re waiting for disk, network or other devices.
If wall clock time > CPU time, you’re waiting for disk, network or other devices.
All are measured in seconds, per the SI.
time [WHAT-EVER-COMMAND]
real 7m2.444s user 76m14.607s sys 2m29.432s $ lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 24
real or wall-clock
real 7m2.444s
On a system with a 24 core-processor, this cmd/process took more than 7 minutes to complete. That by utilizing the most possible parallelism with all given cores.
user
user 76m14.607s
The cmd/process has utilized this much amount of CPU time.
In other words, on machine with single core CPU, the real and user will be nearly equal, so the same command will take approximately 76 minutes to complete.
sys
sys 2m29.432s
This is the time taken by the kernel to execute all the basic/system level operations to run this cmd, including context switching, resource allocation, etc.
Note: The example assumes that your command utilizes parallelism/threads.
Detailed man page: https://linux.die.net/man/1/time
2
Wall clock time is exactly what it says, the time elapsed as measured by the clock on your wall (or wristwatch)
User CPU time is the time spent in «user land», that is time spent on non-kernel processes.
System CPU time is time spent in the kernel, usually time spent servicing system calls.
Sign up or log in
Sign up using Google
Sign up using Facebook
Sign up using Email and Password
Post as a guest
Required, but never shown
Post as a guest
Required, but never shown
performance — Why real time is much higher than «user» and «system» CPU TIME combined?
We have a batch process that executes every day. This week, a job that usually does not past 18 minutes of execution time (real time, as you can see), now is taking more than 45 minutes to finish.
This week, a job that usually does not past 18 minutes of execution time (real time, as you can see), now is taking more than 45 minutes to finish.
Fullstimmer option is already active, but we don’t know why only the real time was increased.
In old documentation there are Fullstimmer stats that could help identify the problem but they do not appear in batch log. (The stats are those down below: Page Faults, Context Switches, Block Operation and so on, as you can see)
It might be an I/O issue. Does anyone know how we can identify if it is really an I/O problem or if it could be some other issue (network, for example)?
To be more specific, this is one of the queries that have increased in time dramatically. As you can see, it is reading from a data base (SQL Server, VAULT schema) and work and writing in work directory.
Number of observations its almost the same:
We asked customer about any change in network traffic, and they said still the same.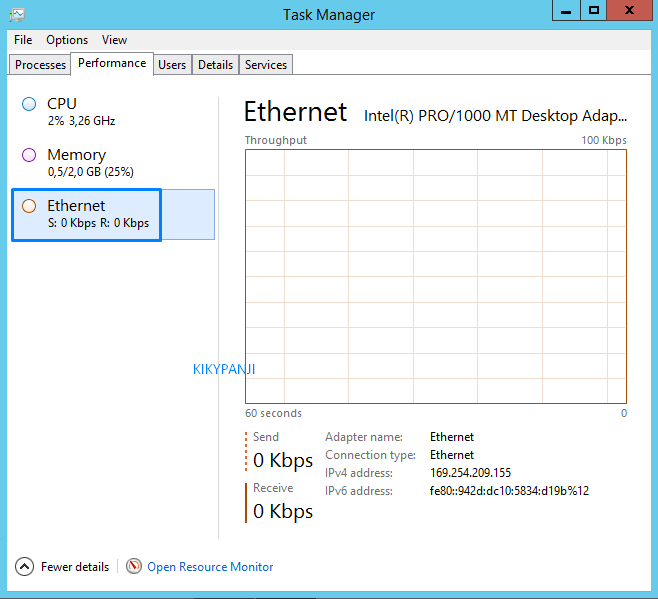
Thanks in advance.
- performance
- debugging
- optimization
- sas
- enterprise-guide
3
For a process to complete, much more needs to be done than the actual calculations on the CPU.
- Your data has te be read and your results have to be written.
- You might have to wait for other processes to finish first, and if your process includes multiple steps, writing to and reading from disk each time, you will have to wait for the CPU each time too.
In our situation, if real time is much larger than cpu time, we usually see much trafic to our Network File System (nfs).
As a programmer, you might notice that storing intermediate results in WORK is more efficient then on remote libraries.
You might safe much time by creating intermediate results as views instead of tables, IF you only use them once. That is not only possible in SQL, but also in data steps like this
data MY_RESULT / view=MY_RESULT;
set MY_DATA;
where transaction_date between '1jan2022'd and 30jun2022'd;
run;
Sign up or log in
Sign up using Google
Sign up using Facebook
Sign up using Email and Password
Post as a guest
Required, but never shown
Post as a guest
Required, but never shown
Lecture 2.
 Processor. Processor operating modes. CPU user registers.
Processor. Processor operating modes. CPU user registers.
|
2.1. CPU. Most
4. Simplified structure of CPU Main
Registers are special memory locations
Arithmetic logic
Block
Clock 2.2. Processor operating modes. Processor 1. 2. 3. 4. 5. At 2.3. Processor registers For
eight
registers
register
pointer register
system
modes Let’s start Basic
Fig. Among 2.4. General registers. 32-bit Others 2.5. segment registers.
using segmented memory models to form any address you need B 2.6. Flag register. More
Fig. 6. Register of flags FLAGS. CF – carry flag. Set to 1, PF — parity flag. Set to 1, AF — half-carry flag or ZF — zero flag. Installed in SF — sign flag. He is always equal to the elder TF — trap flag. He was IF — interrupt flag. Reset this flag to 0 DF OF – overflow flag. He Flags 2.7. Command execution cycle Program For Counter Cycle
Summarize
This |


 All of them are shown in Fig.
All of them are shown in Fig. In addition,
In addition,
 Offset of the next executable command always
Offset of the next executable command always For example, after adding the word 0FFFFh and 1, if the register to which
For example, after adding the word 0FFFFh and 1, if the register to which

 If the instruction uses an operand located in the operational
If the instruction uses an operand located in the operational
User mode and kernel mode — Windows drivers
E-mail address
- Article
- Reading takes 2 minutes
The processor on a Windows-based computer has two different modes: user mode and kernel mode .
The processor switches between two modes depending on the type of code running on the processor. Applications run in user mode, while core operating system components run in kernel mode. Although many drivers run in kernel mode, some drivers can run in user mode.
User mode
When you run an application in user mode, Windows creates process for the application. The process provides the application with a private virtual address space and a private descriptor table . Because the application’s virtual address space is private, one application cannot modify data owned by another application. Each application runs in isolation, and if the application fails, the failure is limited to one application. Other applications and the operating system are not affected by the crash.
The process provides the application with a private virtual address space and a private descriptor table . Because the application’s virtual address space is private, one application cannot modify data owned by another application. Each application runs in isolation, and if the application fails, the failure is limited to one application. Other applications and the operating system are not affected by the crash.
In addition to the private, the user mode application’s virtual address space is limited. A process running in user mode cannot access virtual addresses reserved for the operating system. Restricting the application’s virtual address space in user mode prevents modification and possibly corruption of critical operating system data.
Kernel mode
All code that runs in kernel mode uses the same virtual address space. Thus, a kernel-mode driver is not isolated from other drivers and from the operating system itself. If a kernel-mode driver accidentally writes data to the wrong virtual address, data that belongs to the operating system or another driver may be compromised.