Enabling GPU access with Compose
Important
From the end of June 2023 Compose V1 won’t be supported anymore and will be removed from all Docker Desktop versions.
Make sure you switch to Compose V2 with the
docker composeCLI plugin or by activating the Use Docker Compose V2 setting in Docker Desktop. For more information, see the Evolution of Compose
Compose services can define GPU device reservations if the Docker host contains such devices and the Docker Daemon is set accordingly. For this, make sure you install the prerequisites if you have not already done so.
The examples in the following sections focus specifically on providing service containers access to GPU devices with Docker Compose.
You can use either docker-compose or docker compose commands. For more information, see Evolution of Compose.
Enabling GPU access to service containers
GPUs are referenced in a docker-compose. file using the device structure, within your services that need them. yml
This provides more granular control over a GPU reservation as custom values can be set for the following device properties:
capabilities. This value specifies as a list of strings (eg.capabilities: [gpu]). You must set this field in the Compose file. Otherwise, it returns an error on service deployment.count. This value specified as an integer or the valueallrepresenting the number of GPU devices that should be reserved (providing the host holds that number of GPUs). If nocountis set, all GPUs available on the host are used by default.device_ids. This value specified as a list of strings representing GPU device IDs from the host. You can find the device ID in the output ofnvidia-smion the host. If nodevice_idsare set, all GPUs available on the host used by default.
driver. This value is specified as a string, for exampledriver: 'nvidia'options. Key-value pairs representing driver specific options.
Important
You must set the
capabilitiesfield. Otherwise, it returns an error on service deployment.
countanddevice_idsare mutually exclusive. You must only define one field at a time.
For more information on these properties, see the deploy section in the Compose Specification.
Example of a Compose file for running a service with access to 1 GPU device:
services:
test:
image: nvidia/cuda:10.2-base
command: nvidia-smi
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
Run with Docker Compose:
$ docker compose up Creating network "gpu_default" with the default driver Creating gpu_test_1 ... done Attaching to gpu_test_1 test_1 | +-----------------------------------------------------------------------------+ test_1 | | NVIDIA-SMI 450.80.02 Driver Version: 450.80.02 CUDA Version: 11.1 | test_1 | |-------------------------------+----------------------+----------------------+ test_1 | | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | test_1 | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | test_1 | | | | MIG M. | test_1 | |===============================+======================+======================| test_1 | | 0 Tesla T4 On | 00000000:00:1E.0 Off | 0 | test_1 | | N/A 23C P8 9W / 70W | 0MiB / 15109MiB | 0% Default | test_1 | | | | N/A | test_1 | +-------------------------------+----------------------+----------------------+ test_1 | test_1 | +-----------------------------------------------------------------------------+ test_1 | | Processes: | test_1 | | GPU GI CI PID Type Process name GPU Memory | test_1 | | ID ID Usage | test_1 | |=============================================================================| test_1 | | No running processes found | test_1 | +-----------------------------------------------------------------------------+ gpu_test_1 exited with code 0
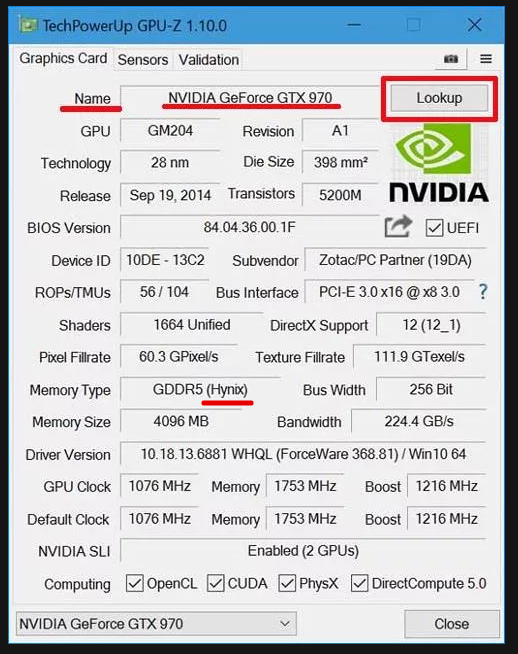
On machines hosting multiple GPUs, device_ids field can be set to target specific GPU devices and count can be used to limit the number of GPU devices assigned to a service container.
You can use count or device_ids in each of your service definitions. An error is returned if you try to combine both, specify an invalid device ID, or use a value of count that’s higher than the number of GPUs in your system.
$ nvidia-smi +-----------------------------------------------------------------------------+ | NVIDIA-SMI 450.80.02 Driver Version: 450.80.02 CUDA Version: 11.0 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00000000:00:1B.0 Off | 0 | | N/A 72C P8 12W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ | 1 Tesla T4 On | 00000000:00:1C.0 Off | 0 | | N/A 67C P8 11W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ | 2 Tesla T4 On | 00000000:00:1D.0 Off | 0 | | N/A 74C P8 12W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ | 3 Tesla T4 On | 00000000:00:1E.0 Off | 0 | | N/A 62C P8 11W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+
Access specific devices
To enable access only to GPU-0 and GPU-3 devices:
services:
test:
image: tensorflow/tensorflow:latest-gpu
command: python -c "import tensorflow as tf;tf. test.gpu_device_name()"
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['0', '3']
capabilities: [gpu]
test.gpu_device_name()"
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['0', '3']
capabilities: [gpu]
Chocolatey Software | GPU-Z (Portable) 2.52.0
Requires Puppet Chocolatey Provider module. See docs at https://forge.puppet.com/puppetlabs/chocolatey.
## 1. REQUIREMENTS ## ### Here are the requirements necessary to ensure this is successful. ### a. Internal/Private Cloud Repository Set Up ### #### You'll need an internal/private cloud repository you can use. These are #### generally really quick to set up and there are quite a few options. #### Chocolatey Software recommends Nexus, Artifactory Pro, or ProGet as they #### are repository servers and will give you the ability to manage multiple #### repositories and types from one server installation. ### b. Download Chocolatey Package and Put on Internal Repository ### #### You need to have downloaded the Chocolatey package as well.#### Please see https://chocolatey.org/install#organization ### c. Other Requirements ### #### i. Requires puppetlabs/chocolatey module #### See https://forge.puppet.com/puppetlabs/chocolatey ## 2. TOP LEVEL VARIABLES ## ### a. Your internal repository url (the main one). ### #### Should be similar to what you see when you browse #### to https://community.chocolatey.org/api/v2/ $_repository_url = 'INTERNAL REPO URL' ### b. Chocolatey nupkg download url ### #### This url should result in an immediate download when you navigate to it in #### a web browser $_choco_download_url = 'INTERNAL REPO URL/package/chocolatey.1.2.1.nupkg' ### c. Chocolatey Central Management (CCM) ### #### If using CCM to manage Chocolatey, add the following: #### i. Endpoint URL for CCM # $_chocolatey_central_management_url = 'https://chocolatey-central-management:24020/ChocolateyManagementService' #### ii.
If using a Client Salt, add it here # $_chocolatey_central_management_client_salt = "clientsalt" #### iii. If using a Service Salt, add it here # $_chocolatey_central_management_service_salt = 'servicesalt' ## 3. ENSURE CHOCOLATEY IS INSTALLED ## ### Ensure Chocolatey is installed from your internal repository ### Note: `chocolatey_download_url is completely different than normal ### source locations. This is directly to the bare download url for the ### chocolatey.nupkg, similar to what you see when you browse to ### https://community.chocolatey.org/api/v2/package/chocolatey class {'chocolatey': chocolatey_download_url => $_choco_download_url, use_7zip => false, } ## 4. CONFIGURE CHOCOLATEY BASELINE ## ### a. FIPS Feature ### #### If you need FIPS compliance - make this the first thing you configure #### before you do any additional configuration or package installations #chocolateyfeature {'useFipsCompliantChecksums': # ensure => enabled, #} ### b.
Apply Recommended Configuration ### #### Move cache location so Chocolatey is very deterministic about #### cleaning up temporary data and the location is secured to admins chocolateyconfig {'cacheLocation': value => 'C:\ProgramData\chocolatey\cache', } #### Increase timeout to at least 4 hours chocolateyconfig {'commandExecutionTimeoutSeconds': value => '14400', } #### Turn off download progress when running choco through integrations chocolateyfeature {'showDownloadProgress': ensure => disabled, } ### c. Sources ### #### Remove the default community package repository source chocolateysource {'chocolatey': ensure => absent, location => 'https://community.chocolatey.org/api/v2/', } #### Add internal default sources #### You could have multiple sources here, so we will provide an example #### of one using the remote repo variable here #### NOTE: This EXAMPLE requires changes chocolateysource {'internal_chocolatey': ensure => present, location => $_repository_url, priority => 1, username => 'optional', password => 'optional,not ensured', bypass_proxy => true, admin_only => false, allow_self_service => false, } ### b.
Keep Chocolatey Up To Date ### #### Keep chocolatey up to date based on your internal source #### You control the upgrades based on when you push an updated version #### to your internal repository. #### Note the source here is to the OData feed, similar to what you see #### when you browse to https://community.chocolatey.org/api/v2/ package {'chocolatey': ensure => latest, provider => chocolatey, source => $_repository_url, } ## 5. ENSURE CHOCOLATEY FOR BUSINESS ## ### If you don't have Chocolatey for Business (C4B), you'll want to remove from here down. ### a. Ensure The License File Is Installed ### #### Create a license package using script from https://docs.chocolatey.org/en-us/guides/organizations/organizational-deployment-guide#exercise-4-create-a-package-for-the-license # TODO: Add resource for installing/ensuring the chocolatey-license package package {'chocolatey-license': ensure => latest, provider => chocolatey, source => $_repository_url, } ### b.
Disable The Licensed Source ### #### The licensed source cannot be removed, so it must be disabled. #### This must occur after the license has been set by the license package. ## Disabled sources still need all other attributes until ## https://tickets.puppetlabs.com/browse/MODULES-4449 is resolved. ## Password is necessary with user, but not ensurable, so it should not ## matter what it is set to here. If you ever do get into trouble here, ## the password is your license GUID. chocolateysource {'chocolatey.licensed': ensure => disabled, priority => '10', user => 'customer', password => '1234', require => Package['chocolatey-license'], } ### c. Ensure Chocolatey Licensed Extension ### #### You will have downloaded the licensed extension to your internal repository #### as you have disabled the licensed repository in step 5b. #### Ensure the chocolatey.extension package (aka Chocolatey Licensed Extension) package {'chocolatey.
extension': ensure => latest, provider => chocolatey, source => $_repository_url, require => Package['chocolatey-license'], } #### The Chocolatey Licensed Extension unlocks all of the following, which also have configuration/feature items available with them. You may want to visit the feature pages to see what you might want to also enable: #### - Package Builder - https://docs.chocolatey.org/en-us/features/paid/package-builder #### - Package Internalizer - https://docs.chocolatey.org/en-us/features/paid/package-internalizer #### - Package Synchronization (3 components) - https://docs.chocolatey.org/en-us/features/paid/package-synchronization #### - Package Reducer - https://docs.chocolatey.org/en-us/features/paid/package-reducer #### - Package Audit - https://docs.chocolatey.org/en-us/features/paid/package-audit #### - Package Throttle - https://docs.chocolatey.org/en-us/features/paid/package-throttle #### - CDN Cache Access - https://docs.
chocolatey.org/en-us/features/paid/private-cdn #### - Branding - https://docs.chocolatey.org/en-us/features/paid/branding #### - Self-Service Anywhere (more components will need to be installed and additional configuration will need to be set) - https://docs.chocolatey.org/en-us/features/paid/self-service-anywhere #### - Chocolatey Central Management (more components will need to be installed and additional configuration will need to be set) - https://docs.chocolatey.org/en-us/features/paid/chocolatey-central-management #### - Other - https://docs.chocolatey.org/en-us/features/paid/ ### d. Ensure Self-Service Anywhere ### #### If you have desktop clients where users are not administrators, you may #### to take advantage of deploying and configuring Self-Service anywhere chocolateyfeature {'showNonElevatedWarnings': ensure => disabled, } chocolateyfeature {'useBackgroundService': ensure => enabled, } chocolateyfeature {'useBackgroundServiceWithNonAdministratorsOnly': ensure => enabled, } chocolateyfeature {'allowBackgroundServiceUninstallsFromUserInstallsOnly': ensure => enabled, } chocolateyconfig {'backgroundServiceAllowedCommands': value => 'install,upgrade,uninstall', } ### e.
Ensure Chocolatey Central Management ### #### If you want to manage and report on endpoints, you can set up and configure ### Central Management. There are multiple portions to manage, so you'll see ### a section on agents here along with notes on how to configure the server ### side components. if $_chocolatey_central_management_url { package {'chocolatey-agent': ensure => latest, provider => chocolatey, source => $_repository_url, require => Package['chocolatey-license'], } chocolateyconfig {'CentralManagementServiceUrl': value => $_chocolatey_central_management_url, } if $_chocolatey_central_management_client_salt { chocolateyconfig {'centralManagementClientCommunicationSaltAdditivePassword': value => $_chocolatey_central_management_client_salt, } } if $_chocolatey_central_management_service_salt { chocolateyconfig {'centralManagementClientCommunicationSaltAdditivePassword': value => $_chocolatey_central_management_client_salt, } } chocolateyfeature {'useChocolateyCentralManagement': ensure => enabled, require => Package['chocolatey-agent'], } chocolateyfeature {'useChocolateyCentralManagementDeployments': ensure => enabled, require => Package['chocolatey-agent'], } }
GPU processing with the Spatial Analyst extension—Help
Available with a Spatial Analyst license.
- How does a GPU work?
- Supported cards and GPU drivers
- GPU configuration
The Spatial Analyst extension now has improved performance and uses the graphics processing unit (GPU) for some tools. In modern computers, this technology takes advantage of the processing power of the video card to improve the performance of certain operations.
GPU support is currently implemented in the following tools:
- Exposure
- Slope
- Mutual Visibility 2
What is the GPU job?
A graphics processing unit (GPU) is a computer hardware component whose main task is to speed up the rendering of graphics on a computer screen. Recently, the computing power of GPU processors has been directed towards performing general computing tasks.
In GPU-based tools, the raster processing task is not directed to the computer’s central processing unit (CPU), but to the graphical GPU. This approach provides a gain when performing operations of a certain type. In such cases, the program breaks the task into many small parts, which are sent to the GPU for processing. Next, the GPU performs the simultaneous processing of all these small tasks, but at a faster speed. The received data is sent back and the software assembles the individual components into the final finished product.
This approach provides a gain when performing operations of a certain type. In such cases, the program breaks the task into many small parts, which are sent to the GPU for processing. Next, the GPU performs the simultaneous processing of all these small tasks, but at a faster speed. The received data is sent back and the software assembles the individual components into the final finished product.
Supported cards and GPU drivers
There are various solutions available on the market for GPU graphics processing. Currently, only NVIDIA GPUs with CUDA processing power version 3.0 or higher are supported. To access this feature, the appropriate card must be installed in the system.
To check the types of graphics cards on a Windows computer, open Device Manager and expand Display adapters. It will list the names and types of your graphics card. If no NVIDIA graphics card is listed, then you will not be able to access this feature and the tool will only use the CPU.
If there is an NVIDIA graphics card, then you need to check the type of graphics processor that is installed in the system using the NVIDIA Control Panel for this:
- Right click on any empty area of the desktop. From the context menu, click NVIDIA Control Panel.
- In the Control Panel window, open the Help menu and click System Information. All NVIDIA graphics card information, driver versions, and other information will be displayed.
Once you have identified your NVIDIA GPU video card type, find its CUDA processing power on the NVIDIA Help page for CUDA GPUs. In the corresponding section, find your GPU board and take note of the Compute Power value listed for it. This value must be equal to or greater than 3.0.
The graphics card installed on computers comes with a default driver. Before running an analysis tool that uses the GPU, you must update your GPU graphics card to the latest version available on the NVIDIA driver update — page.
GPU configuration
This tool will use only one GPU for computing operations. But, if you have only one GPU in your computer, then it will be used for both visualization and computational operations. In this case, a warning message will appear during the execution of the tool, indicating that the display may become unresponsive. Therefore, it is recommended to use two GPUs for spatial analysis: one for visualization and one for computational operations.
When multiple GPUs are used in the system, the first GPU in TCC (Tesla Compute Cluster) driver mode will be used by default. If there is no GPU in TCC driver mode, then the first GPU (with index 0) will be used unless otherwise specified. To specify the GPU or disable it, see the following:
- To use a different GPU, you can specify it using the CUDA_VISIBLE_DEVICES system environment variable. To do this, first create this variable if it has not previously been created in the system. Then set its value to the index value (0 for the first, 1 for the second, and so on) representing the GPU device you would like to use and restart the application.
- If you do not want the analysis to use any of the GPU devices installed in the system, then you can set the CUDA_VISIBLE_DEVICES system environment variable to -1 and restart the application. After that, the tool will be executed only by the CPU.
- To switch back to using the GPU, either delete the CUDA_VISIBLE_DEVICES system environment variable or set it to the GPU device you want to use and then restart the application.
See the CUDA Toolkit Programming Guide for more information about this CUDA_VISIBLE_DEVICES system environment variable.
The following subsections provide guidance on setting up the configuration for optimal performance using the capabilities of the GPU.
TCC Driver Configuration
For NVIDIA GPUs, the GPU device used for computing must use the TCC driver, not the default Windows Display Driver Model (WDDM). TCC mode allows the GPU to work more efficiently.
To enable TCC driver mode, use the NVIDIA System Management Interface daemon, usually found in C:\Program Files\NVIDIA Corporation\NVSMI\nvidia-smi. exe. For example, the command ‘nvidia-smi -dm 1 -i 2’ switches the graphics card with device ID 2 to display mode 1 (TCC).
exe. For example, the command ‘nvidia-smi -dm 1 -i 2’ switches the graphics card with device ID 2 to display mode 1 (TCC).
Note:
If you are using ArcGIS Server, the GPU used for compute must be in TCC driver mode.
Disable ECC mode
Disable Error Correcting Code (ECC) mode for the GPU used for computing because it reduces the amount of memory available to that GPU.
To disable ECC mode, use the NVIDIA System Management Interface (nvidia-smi) control program, usually found in C:\Program Files\NVIDIA Corporation\NVSMI\nvidia-smi.exe. For example, the command ‘nvidia-smi -e 0 -i 1’ disables the ECC mode of the GPU with device ID 1.
Changing TDR settings
When a GPU used for compute processes is in WDDM driver mode, the Windows display device driver may reset that GPU if any of these processes take more than 2 seconds. This is called a condition for Windows Timeout Detection and Recovery (TDR). In this case, the tool will not be completed and a GPU error will be displayed.
It is possible to change the registry key, TdrDelay, to avoid this scenario. By setting a suitable value (for example, 60 seconds), the time will allow the work to complete before the TDR condition is triggered. On most Windows systems, the path to the TdrDelay key in the Registry is HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\GraphicsDrivers. If the TdrDelay key does not exist, it must be created in this location. Note that when creating or modifying this registry value, you must first back up the registry. You must restart your computer for the changes to take effect. The Microsoft Developers Network has more information on setting TDR Delay.
Caution:
Esri cannot be held responsible for any problems that may occur if the registry is modified incorrectly. Take the proper steps to make sure you have a valid registry backup to restore your system in case of any problems, or seek help from a qualified systems analyst to make changes to the registry.
Related topics
Found a way to enable GPU virtualization for GeForce 9 series cards0001
Blogs
goldas The post has been rewarded
This opens up great opportunities for Internet cafes and gaming clubs
recommendations
The function of artificially splitting video card resources into several virtual tasks is currently limited to Grid/Tesla and workstations with Quadro GPUs. This feature is not available for the GeForce gaming series. At least, this was not possible until now. Thanks to a fairly simple module called «vgpu_unlock» this feature can now be enabled in consumer graphics cards.
This feature is not available for the GeForce gaming series. At least, this was not possible until now. Thanks to a fairly simple module called «vgpu_unlock» this feature can now be enabled in consumer graphics cards.
GPU virtualization is a way of virtually allocating graphics card hardware resources among several different tasks. This allows multiple end users to use the same graphics card for multiple tasks such as 3D modeling or scientific work. Many users use this technology without knowing it themselves. For example, the popular gaming platform GeForce Now works on this principle. In it, NVIDIA uses GRID GPUs to virtualize multiple gaming environments for gamers.
Theoretically, it should now be possible to enable one GeForce RTX 3090 graphics card to run multiple virtual machines and use it for gaming. This would be an interesting solution to the lack of graphics cards. This feature can be especially useful in various Internet cafes and computer clubs, which can use one GPU to run several computers.
The mod is actually quite simple, it tricks the driver into reading a different PCI device ID. Cards based on Pascal, Turing and Ampere architectures are interpreted by the driver as Quadro or Tesla cards. The mod works with Linux and KVM virtual machine software. Although the host computer cannot run on the Microsoft Windows operating system, the virtual machines that will be connected to the host system have this capability.
So the driver looks at the PCI device ID to determine if a particular GPU supports vGPU functionality. This ID, along with the PCI Vendor ID, is unique for each device type. To enable vGPU support, you need to tell the driver that the PCI device ID of the installed GPU is one of the device IDs used by the vGPU-enabled GPU.
The list of all currently supported video cards is quite extensive. You can check it out by looking at the image below.
recommendations
This material was written by a site visitor and has been rewarded.